Contents
Introduction
This self-contained library is intended to aid in parsing dates and time values regardless of incoming format, and output the result to a uniform format of choice.
The simple fact is that client side inputs are notoriously unreliable. Even when enforcing inputs to choose or sanitize dates, you may not end up with uniform results across browsers. Or even the SAME browser. Google Chrome for instance, will send a different format depending upon seconds input. Even if you enforce seconds using the step attribute, Chrome will not send seconds as part of the date time string if the user chooses a seconds value of 00.
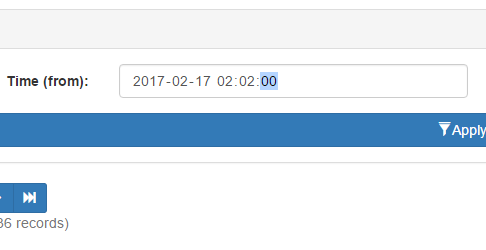
Unless you choose a value of 01 or greater, Chrome simply won’t include seconds.
However, should you choose a seconds value of 01 or more, then Chrome WILL include the seconds when posting. Same browser. Same version. Same field attributes. Yet entirely different formats depending on perfectly valid user inputs.
You could choose to use text fields and invoke heavy JavaScript date/time pickers, but then you harm the mobile experience, where seamless date choosing is already implemented. If you choose a dynamic solution that looks for support of date time fields, then you regain the mobile experience, but you’re right back to dealing with unreliable formatting.
In a nutshell, if you don’t perform server side validation, you may wind up with undefined behavior from whatever code relies on the input. Databases are particularly finicky. Go ahead and send client side dates directly to an RDMS. Your results will be the same as Forrest Gump’s chocolate box.
Unfortunately, most forms of server side validation are themselves rather persnickety. In the above example, a validator expecting seconds will reject input from Chrome, and several mobile browsers as well. This is where my date and time library comes into play. By leveraging a layered approach and PHP’s string to time, we can accept most any valid time string, verify it, and output in a single uniform format for use.
Use
Simple – Object is initialized with default settings:
// Initialize object with default settings. $dc_time = new dc\Chronofix();
Advanced – Initializing a settings object first, and applying it to the main object.
// Initialize settings object, and use it
// to set date format to Year-Month-Day only.
$dc_time_settings = new dc\Config()
(); $dc_time_settings->set_format('Y-m-d'); // Initialize time library with settings. $dc_time = new dc\Chronofix($dc_time_settings);
Once initialized the following functions are exposed. All examples assume default settings.
Settings Object
Again be aware settings are entirely optional.
echo $settings->get_format(); // Outputs Y-m-d H:i:s
Returns the format string currently in use.
$string = 'Y-m-d H:i:s'; $settings->set_format($string);
Replaces format in use with $string.
Time Object
$object = $time->get_settings();
Returns a reference to settings object in use by time object. By accessing the current settings object, you can modify settings at runtime.
echo $time->get_time(); // Outputs 2017-02-15 12:00:00
Returns the current date/time value as a string.
$string = '2017-02-15 12:00:00'; echo $time->is_valid($string); // Outputs TRUE if valid, or FALSE.
For internal use, but exposed for possible utility purposes. Evaluates $string against current date/time format. If the formats match, TRUE is returned. Otherwise FALSE is returned.
echo $time->sanitize(); // Outputs 2017-02-15 12:00:00
Evaluates the current date/time value and attempts to convert its format to the current format setting. Leverages a combination of php’s strtotime and date object to handle nearly any format of dates and times. Outputs newly formatted date/time string, or NULL on failure.
$object = new dc\Config(); $time->set_settings($object);
Replaces current settings object with $object.
$string = '2017-02-15 12:00:00'; $time->set_time($string);
Replaces the current date/time string with $string. You will need to do this before performing any other operations.
Source
Full source available on Github.