Racism is a problem. Let’s get that out-of-the-way right away. But as with any real problem, injecting it as a narrative into every known facet of society or life rarely produces any working solution.
Moreover it seems, that due to the political sensitivity of racism as a topic, scientific method no longer applies as a ground rule of discussion. As a primary example, let us look at the opening quotation of an article published by The Eastern Sociological Society: Priming Implicit Racism in Television News: Visual and Verbal Limitations on Diversity.
See Sonnett, J., Johnson, K. A., & Dolan, M. K. (2015). Priming Implicit Racism in Television News: Visual and Verbal Limitations on Diversity. Sociological Forum,30(2), 328-347
We highlight an understudied aspect of racism in television news, implicit racial cues found in the contradic-
tions between visual and verbal messages. We compare three television news broadcasts from the first week
after Hurricane Katrina to reexamine race and representation during the disaster. Drawing together insights
from interdisciplinary studies of cognition and sociological theories of race and racism, we examine how
different combinations of the race of reporters and news sources relate to the priming of implicit racism. We
find racial cues that are consistent with stereotypes and myths about African Americans
—
even in broadcasts
featuring black reporters
—
but which appear only in the context of color-blind verbal narration. We conclude
by drawing attention to the unexpected and seemingly unintended reproduction of racial ideology.
In fairness, the article does not present itself as research topic, but still is written from a standpoint of unequivocal truth to reference. The conclusion is simply accepted, and then supported with the author’s findings. That is a scary precedent to set.
In further fairness, I’ve just described the lion’s share of writings – certainly most of my own. Throwing rocks from a glass house isn’t the point of this writing. I would simply ask a question about the directed efforts: Is our quest for harmony a hindrance to handling disasters?
In ~twenty pages, not once did Sonnett, Johnson or Dolan mention any of the staggering logistic issues Hurricane Katrina presented and how this alone might have affected a view of racial bias. Hurricanes are not people. They don’t care about race. They DO care about class however, as it just so happens the poorest members of society are also the least mobile, the most vulnerable, and in the aftermath, justifiably the most desperate. Naturally class disparity is a topic all its own, but one that goes far beyond this writing.
Efforts to politicize Katrina aren’t hard to find: Teme’ (2009-2014), If Good Is Willing and The Creeks Don’t Rise (2009),Trouble The Water (2008), and When The Leeve’s Broke – A Requiem In Four Acts (2006) are all a cursory Google search away. Analysis of the logistical efforts, finances, water tables, meteorological phenomenon (that don’t also lapse into politicized climate change discourse) are a bit harder to come by.
The later is where I found need to question our directed efforts. Racial equality is a worthy discussion and has its place. But should it really be the primary focus of disaster aftermath? Perhaps we should make a little room for discussion about real preparation, mitigation, and response.
Think you’re ready for anything? VivosxPoint would like a word with you. Why bother stocking piling supplies, training yourself, or being aware of the situation at all? Vivos promises Life Assurance – for a price.
This author must ask right away, exactly how would a “life assurance” guarantee work? By definition, you’re not likely to have unsatisfied customers. Vivos seems to believe the solution is to lease bunkers in the long abandoned Fort Igloo. Welcome to the xPoint Survival Community (http://www.terravivos.com/secure/vivosxpoint.htm), brainchild of founder Robert Vicino.
The massive complex is spread over a sprawling and remote, off-grid area of approximately 18-square miles. It is strategically and centrally located in one of the safest areas of North America, at a high and dry altitude of 3,800 feet, relatively mild weather and well inland from all large bodies of water. It is over 100 miles from the nearest known military nuclear targets.
Additionally, Vivios promises 24-7 security, monitoring, and for those willing to pay, all amenities provided. Do it yourself types are welcome too. Just sign on for the ninety-nine year bunker lease and season to fit. All for the low, low price of 25K USD.
If any of this rings sarcastic, it’s not by accident. I’m being generous opining the practicality is questionable. At best. The very slogan found on Vivos own site borders on hilarity.
When it comes to survival, it is not how close or the proximity of your shelter that matters; what does matter is the survivability!
Sure. For when the end comes, no doubt getting from a Manhatten loft or an LA suburb to your bulletproof bunker in the nation’s breadbasket won’t be an issue at all.
Survival comes in many forms. Awareness. Training. Equipment. Yes, shelter. Sadly, even a bit of luck at times. A fortified pillbox in what is to most of us the middle of nowhere sounds great if you can afford it, but does little to fulfill basic needs in a real disaster. After all, you have to live long enough to get there first. Might I suggest a bit of free CERT training and keeping some basic needs on hand? You won’t get a Life Assurance guarantee, but you might get a better assurance on life.
Disaster preparation is an extensive and potentially expensive business. Distilled to materials alone, nearly any advice on how to stock for the unexpected tends to include lengthy material bullet lists. Comprehensive lists might look great on paper, but are they realistic compared to the limits of a typical families’ personal resources?
Let’s look at a single item as suggested in CERT UNIT 1: DISASTER PREPAREDNESS
PARTICIPANT MANUAL, 1-22: Water.
Keep in mind that a normally active person needs to drink at least 2 quarts of water each day. Hot environments and intense physical activity can double that requirement. Children, nursing mothers, and ill people will need more.
Store 1 gallon of water per person per day (2 quarts for drinking, 2 quarts for food preparation and sanitation).*
Keep at least a 3-day supply of water for each person in your household.
Seems simple enough, until one begins to do the math. Following the above guidelines a family of four would need to keep twelve gallons of water on hand at all times, making sure to replenish the supply at regular intervals. Do you have the ten or so square feet needed to spare? Can your drywall-mounted shelves withstand one hundred pounds?
What about poorer families? Those who do not have space or money to spare on day-to-day resources, let alone extra water jugs? Moreover, these same families are typically more vulnerable to disasters in general. As an alternative, single step filtration straws could offer drinking water for a lesser expenditure of space, money, and time.
All the above merely covers water, arguably the easiest necessity to acquire. I would suggest looking at all areas of disaster preparation not just from the disaster itself, but also from the standpoint of limited availability. This article lacks the necessary scope or research to back up the concerns presented, but I hope to invoke some discussion and further examination. Preparation guidelines tailored more to the limits of its target audience might be less than ideal, but they would be a vast improvement over the nothing that may result from more lofty expectations.
Zombies, zombies, zombies… look about and you will find them permeating nearly every aspect of contemporary culture. I would honestly doubt a real Zombie invasion would provide so many sightings of our favorite shambling obsessions.
With that in mind, to find Zombies being exploited for any number of topics need nothing more than a cursory search. Survival tips are no exception.
BUDK is but one of many outfitter companies caught in the Zombie invasion. While their “tips” shown here might be an obvious ploy for sales, the ideas given are not entirely nonsense – be it wilderness treks or an urban blackout. Taken with a grain of water purifying iodine of course.
Lifestraw Personal Water Filter – In any given disaster, water is an immediate and obvious need even the most sheltered suburbanite is aware of. Unfortunately procurement is not as forefront. Recommended storage of one gallon per day for each individual borders on impractical for many families. Purifying is the next best step, but even in the best of times it is a process the untrained would find rather enigmatic. A single step item that combines simplicity with compact storage is a great combination for busy families looking attempting preparations but unable or unwilling to devote a great deal of personal resources.
Stormproof Matches – Another great item that satisfies a need most know of but few know about. The article makes a point to speak of durability, but the associated longevity might prove more important when an emergency kit long forgotten is suddenly forced out of mothballs.
One Person Tent – Great for wilderness survival. For a family huddled around their NOAA radio, probably a nicety best left to more lavish budgets.
Axe – I can’t see the value in the particular item advertised, but they aren’t wrong about the need for an axe or hatchet. Any outdoor or hardware supplier will have a more practical version on hand. But do make sure to get stainless steel.
Bicycle – Can’t get them all right! Bicycles are fantastic, but for reasons outside the purview of disaster preparation. Sure, they’d have enormous value in a long-term situation, but bicycles won’t do anyone much good during those crucial aftermath hours.
Five tips, and three on the money? You could do worse learning how to stay alive from a writing about dead folks. Remember to take their (and my) advice in accordance with your own needs. Stay safe!
Dr. Kruvand and Dr. Bryant sought out to discover if the CDC’s now famous Zombie Apocalypse campaign produced positive results in disaster preparation. They reached a fairly straight forward conclusion: No.
Public Health Reports / November–December 2015 / Volume 130 – Page 662
Although the campaign garnered
substantial attention, this study suggests that it was not
fully capable of achieving CDC’s goals of education and
action.
With respect to the research and groundwork laid out in Dr. Kruvand and Dr. Braynt’s study, I must respectfully, but vehemently disagree. It is true that instantaneously quantifiable results did not see significant change vs. a control group. However, it is also true that a campaign established in 2011 continues to attract attention and discussion in 2018. This intangible result has even filtered its way into classrooms, now serving as the target metaphor in the very course this assignment was crafted for.
One might compare the CDC Zombies to the mascot of a sports team. He, she, or it has no short-term effect on the outcome of an individual game. Rather, the mascot serves as an emotional focal point for support efforts. In turn, those efforts may attract attention and resources in the form of greater financial influx, superior staff, and more player talent that ultimately translates to success on the scoreboard. So it is that while a single campaign alone may not have sent John Q. off to pack supplies, it can and has served as a proverbial lighting rod to education and public service alerts for the better part of seven years. Those intangible results may well be far more valuable in the long-term than a year of boosted preparedness statistics.
Working with text strings in C is the kind of 04:00 in the morning, keyboard smashing, programing purgatory most of us wouldn’t wish on our most anorak frenemy. No worries though right? You finally got your brilliant 50K creation compiled and ready to unleash upon the world.
Then it returns a week later in pieces, hacked apart at the seams. Evidently your personal take on Snake is to blame for shutting down the CIA, dumping Experian’s data coffers, and exposing Anna Kendrick’s Playboy negatives. Oops.
Should have sanitized that name input…
Buffer overflows are one of the oldest, most exploited, and on the surface truly asinine flaws in the computer industry today. Yet they stubbornly persist despite all efforts, begging the simple questions of how, and why?
This article, written by Perter Bright is one of the most comprehensive and well penned answers I believe you’ll find. Given the finicky nature of the net (Link rot for everyone!), a copy in full also appears below. I highly recommend you take a look.
How security flaws work: The buffer overflow
Starting with the 1988 Morris Worm, this flaw has bitten everyone from Linux to Windows.
The buffer overflow has long been a feature of the computer security landscape. In fact the first self-propagating Internet worm—1988’s Morris Worm—used a buffer overflow in the Unix finger daemon to spread from machine to machine. Twenty-seven years later, buffer overflows remain a source of problems. Windows infamously revamped its security focus after two buffer overflow-driven exploits in the early 2000s. And just this May, a buffer overflow found in a Linux driver left (potentially) millions of home and small office routers vulnerable to attack.
At its core, the buffer overflow is an astonishingly simple bug that results from a common practice. Computer programs frequently operate on chunks of data that are read from a file, from the network, or even from the keyboard. Programs allocate finite-sized blocks of memory—buffers—to store this data as they work on it. A buffer overflow happens when more data is written to or read from a buffer than the buffer can hold.
On the face of it, this sounds like a pretty foolish error. After all, the program knows how big the buffer is, so it should be simple to make sure that the program never tries to cram more into the buffer than it knows will fit. You’d be right to think that. Yet buffer overflows continue to happen, and the results are frequently a security catastrophe.
To understand why buffer overflows happen—and why their impact is so grave—we need to understand a little about how programs use memory and a little more about how programmers write their code. (Note that we’ll look primarily at the stack buffer overflow. It’s not the only kind of overflow issue, but it’s the classic, best-known kind.)
Stack it up
Buffer overflows create problems only for native code—that is, programs which use the processor’s instruction set directly rather than through some intermediate form such as in Java or Python. The overflows are tied to the way the processor and native code programs manipulate memory. Different operating systems have their own quirks, but every platform in common use today follows essentially the same pattern. To understand how these attacks work and some of the things people do to try to stop them, we first have to understand a little about how that memory is used.
The most important central concept is the memory address. Every individual byte of memory has a corresponding numeric address. When the processor loads and stores data from main memory (RAM), it uses the memory address of the location it wants to read and write from. System memory isn’t just used for data; it’s also used for the executable code that makes up our software. This means that every function of a running program also has an address.
In the early days of computing, processors and operating systems used physical memory addresses: each memory address corresponded directly to a particular piece of RAM. While some pieces of modern operating systems still have to use these physical memory addresses, all of today’s operating systems use a scheme called virtual memory.
With virtual memory, the direct correspondence between a memory address and a physical location in RAM is broken. Instead, software and the processor operate using virtual memory addresses. The operating system and processor together maintain a mapping between virtual memory addresses and physical memory addresses.
This virtualization enables a range of important features. The first and foremost is protected memory. Every individual process gets its own set of addresses. For a 32-bit process, those addresses start at zero (for the first byte) and run up to 4,294,967,295 (or in hexadecimal, 0xffff'ffff; 232 – 1). For a 64-bit process, they run all the way up to 18,446,744,073,709,551,615 (0xffff'ffff'ffff'ffff, 264 – 1). So, every process has its own address 0, its own address 1, its own address 2, and so on and so forth.
(For the remainder of this article, I’m going to stick to talking about 32-bit systems, except where otherwise noted. 32- and 64-bit systems work in essentially the same ways, so everything translates well enough; it’s just a little clearer to stick to one bitness.)
Because each process gets its own set of addresses, these scheme in a very straightforward way to prevent one process from damaging the memory of any other: all the addresses that a process can use reference memory belonging only to that process. It’s also much easier for the processes to deal with; physical memory addresses, while they broadly work in the same way (they’re just numbers that start at zero), tend to have wrinkles that make them annoying to use. For example, they’re usually not contiguous; address 0x1ff8'0000 is used for the processor’s System Management Mode memory; a small chunk of physical memory that’s off limits to normal software. Memory from PCIe cards also generally occupies some of this address space. Virtual addresses have none of these inconveniences.
So what does a process have in its address space? Broadly speaking, there are four common things, of which three interest us. The uninteresting one is, in most operating systems, “the operating system kernel.” For performance reasons, the address space is normally split into two halves, with the bottom half being used by the program and the top half being the kernel’s address space. The kernel-half of the memory is inaccessible to the program’s half, but the kernel itself can read the program’s memory. This is one of the ways that data is passed to kernel functions.
The first things that we need to care about are the executables and libraries that constitute the program. The main executable and all its libraries are all loaded into the process’ address space, and all of their constituent functions accordingly have memory addresses.
The second is the memory that the program uses for storing the data it’s working on, generally called the heap. This might be used, for example, to store the document currently being edited, the webpage (and all its JavaScript objects, CSS, and so on) being viewed, or the map for the game being played.
The third and most important is the call stack, generally just called the stack. This is the most complex aspect. Every thread in a process has its own stack. It’s a chunk of memory that’s used to keep track of both the function that a thread is currently running, as well as all the predecessor functions—the ones that were called to get to the current function. For example, if function a calls function b, and function b calls function c, then the stack will contain information about a, b, and c, in that order.
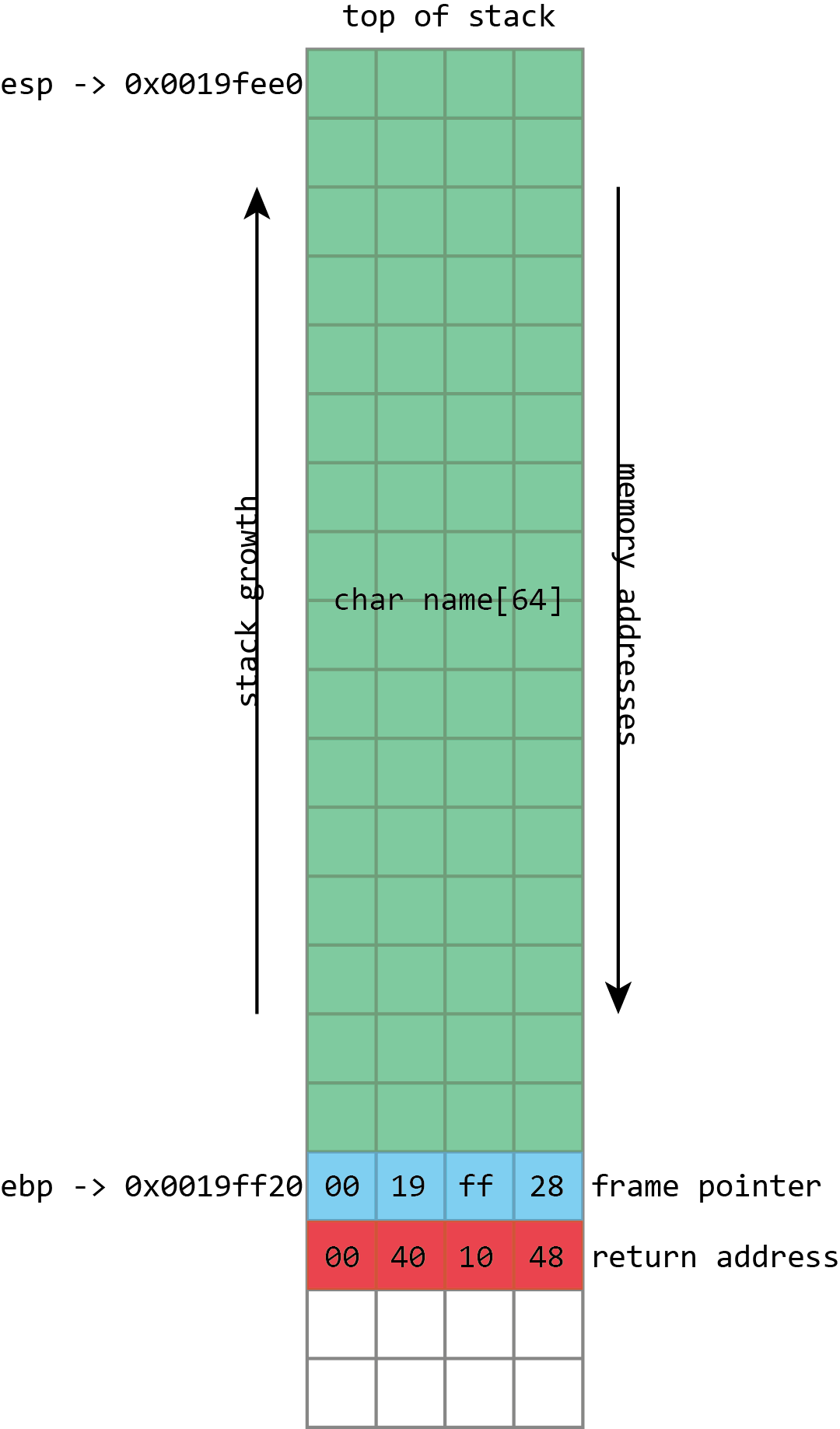
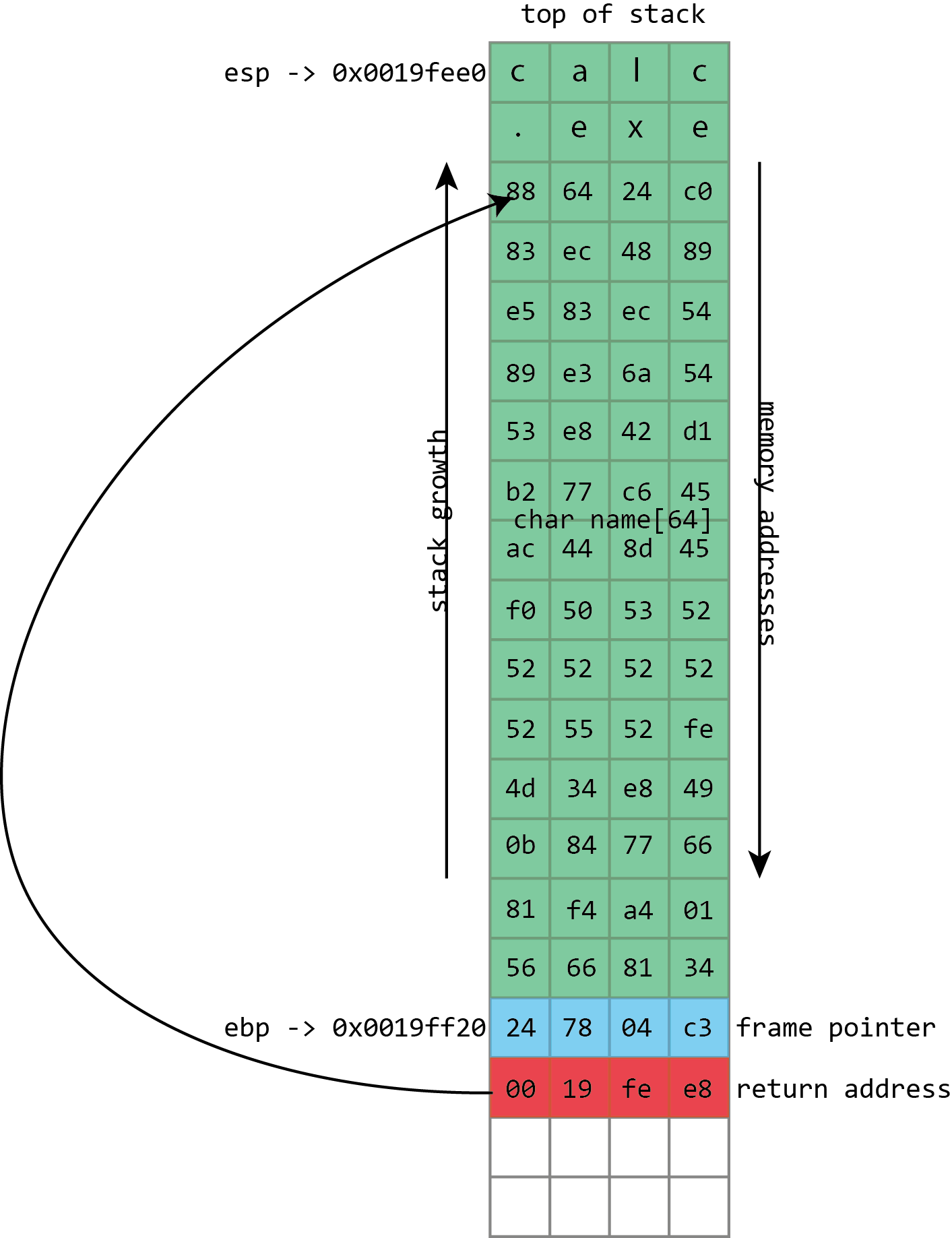
Here we see the basic layout of our stack with a 64 character buffer called name, then the frame pointer, and then the return address. esp has the address of the top of the stack, ebp has the address of the frame pointer.
The call stack is a specialized version of the more general “stack” data structure. Stacks are variable-sized structures for storing objects. New objects can be added (“pushed”) to one end of the stack (conventionally known as the “top” of the stack), and objects can be removed (“popped”) from the stack. Only the top of the stack can be modified with a push or a pop, so the stack forces a kind of sequential ordering: the most recently pushed item is the one that gets popped first. The first item that gets pushed on the stack is the last one that gets popped.
The most important thing that the call stack does is to store return addresses. Most of the time, when a program calls a function, that function does whatever it is supposed to do (including calling other functions), and then returns to the function that called it. To go back to the calling function, there must be a record of what that calling function was: execution should resume from the instruction after the function call instruction. The address of this instruction is called the return address. The stack is used to maintain these return addresses: whenever a function is called, the return address is pushed onto the stack. Whenever a function returns, the return address is popped off the stack, and the processor begins executing the instruction at that address.
This stack functionality is so fundamentally important that most, if not all, processors include built-in support for these concepts. Consider x86 processors. Among the registers (small storage locations in the processor that can be directly accessed by processor instructions) that x86 defines, the two that are most important are eip, standing for “instruction pointer,” and esp, standing for stack pointer.
esp always contains the address of the top of the stack. Each time something is pushed onto the stack, the value in esp is decreased. Each time something is popped from the stack, the value of esp is increased. This means that the stack grows “down;” as more things are pushed onto the stack, the address stored in esp gets lower and lower. In spite of this, the memory location referenced by esp is still called the “top” of the stack.
eip gives the address of the currently executing instruction. The processor maintains eip itself. It reads the instruction stream from memory and increments eip accordingly so that it always has the instruction’s address. x86 has an instruction for function calls, named call, and another one for returning from a function, named ret.
call takes one operand; the address of the function to call (though there are several different ways that this can be provided). When a call is executed, the stack pointer esp is decremented by 4 bytes (32-bits), and the address of the instruction following the call, the return address, is written to the memory location now referenced by esp—in other words, the return address is pushed onto the stack. eip is then set to the address specified as operand to call, and execution continues from that address.
ret does the opposite. The simple ret doesn’t take any operands. The processor first reads the value from the memory address contained in esp, then increments esp by 4 bytes—it pops the return address from the stack. eip is set to this value, and execution continues from that address.
If the call stack only contained a sequence of return addresses, there wouldn’t be much scope for problems. The real problem comes with everything else that goes on the stack, too. The stack happens to be a quick and efficient place for storing data. Storing data on the heap is relatively complex; the program needs to keep track of how much space is available on the heap, how much space each piece of data is using, and various other bits of bookkeeping. But the stack is also simple; to make space for some data, just decrement the stack pointer. To tidy up when the data is no longer needed, increment the stack pointer.
This convenience makes the stack a logical place to store the variables that belong to a function. A function has a 256 byte buffer to read some user input? Easy, just subtract 256 from the stack pointer and you’ve created the buffer. At the end of the function, just add 256 back onto the stack pointer, and the buffer is discarded.
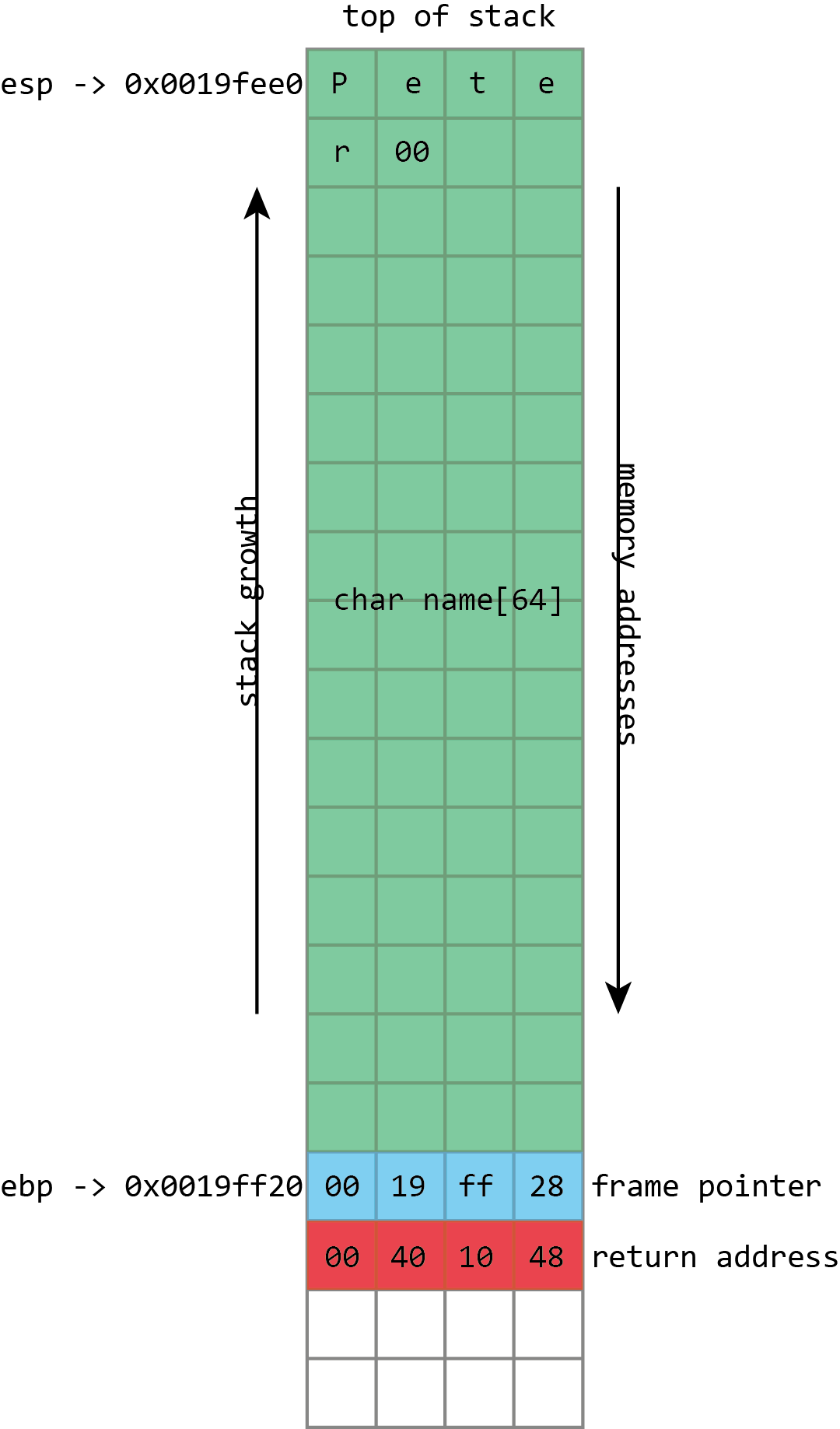
When we use the program correctly, the keyboard input is stored in the name buffer, followed by a null (zero) byte. The frame pointer and return address are unaltered.
There are limitations to this. The stack isn’t a good place to store very large objects; the total amount of memory available is usually fixed when a thread is created, and that’s typically around 1MB in size. These large objects must be placed on the heap instead. The stack also isn’t usable for objects that need to exist for longer than the span of a single function call. Because every stack allocation is undone when a function exits, any objects that exist on the stack can only live as long as a function is running. Objects on the heap, however, have no such restriction; they can hang around forever.
This stack storage isn’t just used for the named variables that programmers explicitly create in their programs; it can also be used for storing whatever other values the program may need to store. This is traditionally a particularly acute concern on x86. x86 processors don’t have very many registers (there are only 8 integer registers in total, and some of those, like eip and esp, already have special purposes), and so functions can rarely keep all the values they need in registers. To free up space in a register while still ensuring that its current value can be retrieved later, the compiler will push the value of the register onto the stack. The value can then be popped later to put it back into a register. In compiler jargon, this process of saving registers so that they can be re-used is called spilling.
Finally, the stack is often used to pass arguments to functions. The calling function pushes each argument in turn onto the stack; the called function can then pop the arguments off. This isn’t the only way of passing arguments—they can be passed in registers too, for example—but it’s one of the most flexible.
The set of things that a function has on the stack—its local variables, its spilled registers, and any arguments it’s preparing to pass to another function—is called a “stack frame.” Because data within the stack frame is used so extensively, it’s useful to have a way of quickly referencing it.
The stack pointer can do this, but it’s somewhat awkward: the stack pointer always points to the top of the stack, and so it moves around as things are pushed and popped. For example, a variable may start out with an address of at esp + 4. Two more values might be pushed onto the stack, meaning that the variable now has to be accessed at esp + 12. One of those values can then get popped off, so the variable is now at esp + 8.
This isn’t an insurmountable difficulty, and compilers can easily handle the challenge. Still, it can make using the stack pointer to access anything other than “the top of the stack” awkward, especially for the hand-coded assembler.
To make things easier, it’s common to maintain a second pointer, one that consistently stores the address of the bottom (start) of each stack frame—a value known as the frame pointer—and on x86, there’s even a register that’s generally used to store this value, ebp. Since this never changes within a given function, this provides a consistent way to access a function’s variables: a value that’s at ebp - 4 will remain at ebp - 4 for the whole of a function. This isn’t just useful for humans; it also makes it easier for debuggers to figure out what’s going on.
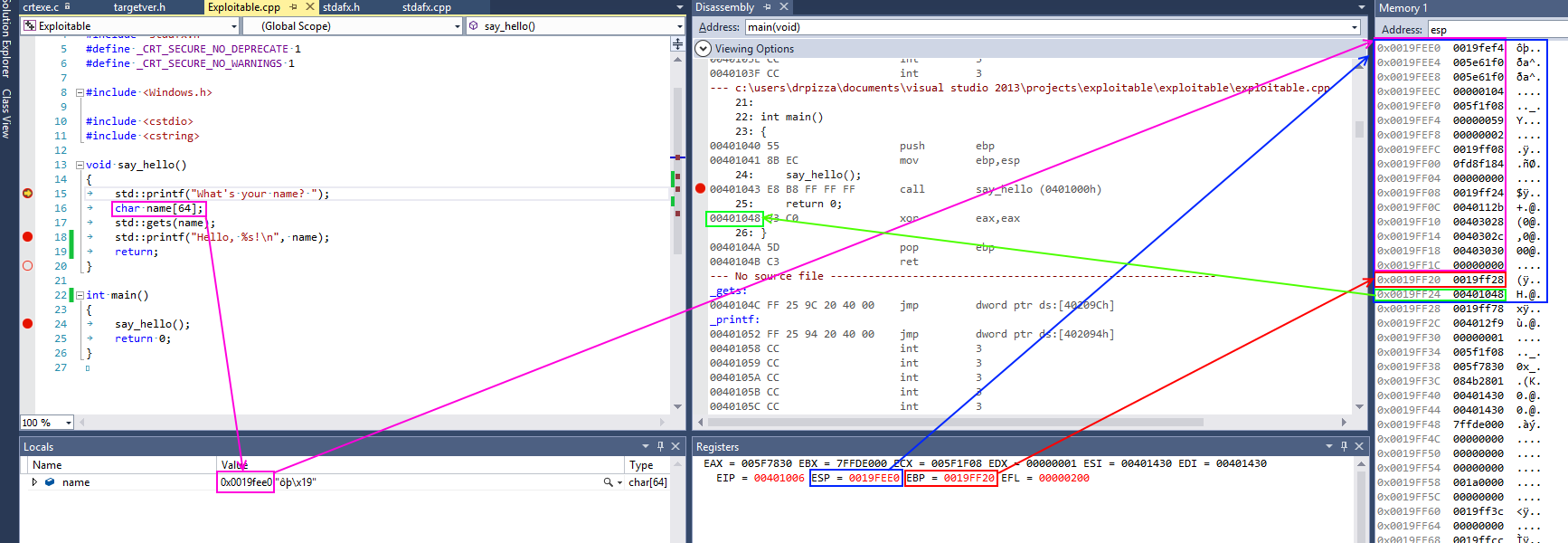
This screenshot from Visual Studio shows some of this in action for a simple x86 program. On x86 processors, the register named esp contains the address of the top stack, in this case 0x0019fee0, highlighted in blue (on x86, the stack actually grows downwards, toward memory address 0, but it’s still called the top of the stack anyway). This function only has one stack variable, name, highlighted in pink. It’s a fixed size 32-byte buffer. Because it’s the only variable, its address is also 0x0019fee0, the same as the top of the stack.x86 also has a register called ebp, highlighted in red, that’s (normally) dedicated to storing the location of the frame pointer. The frame pointer is placed immediately after the stack variables. Right after the frame pointer is the return address, highlighted in green. The return address references a code fragment with address 0x00401048. This instruction comes immediately after a call instruction, making clear the way the return address is used to resume execution from where the calling function left off.
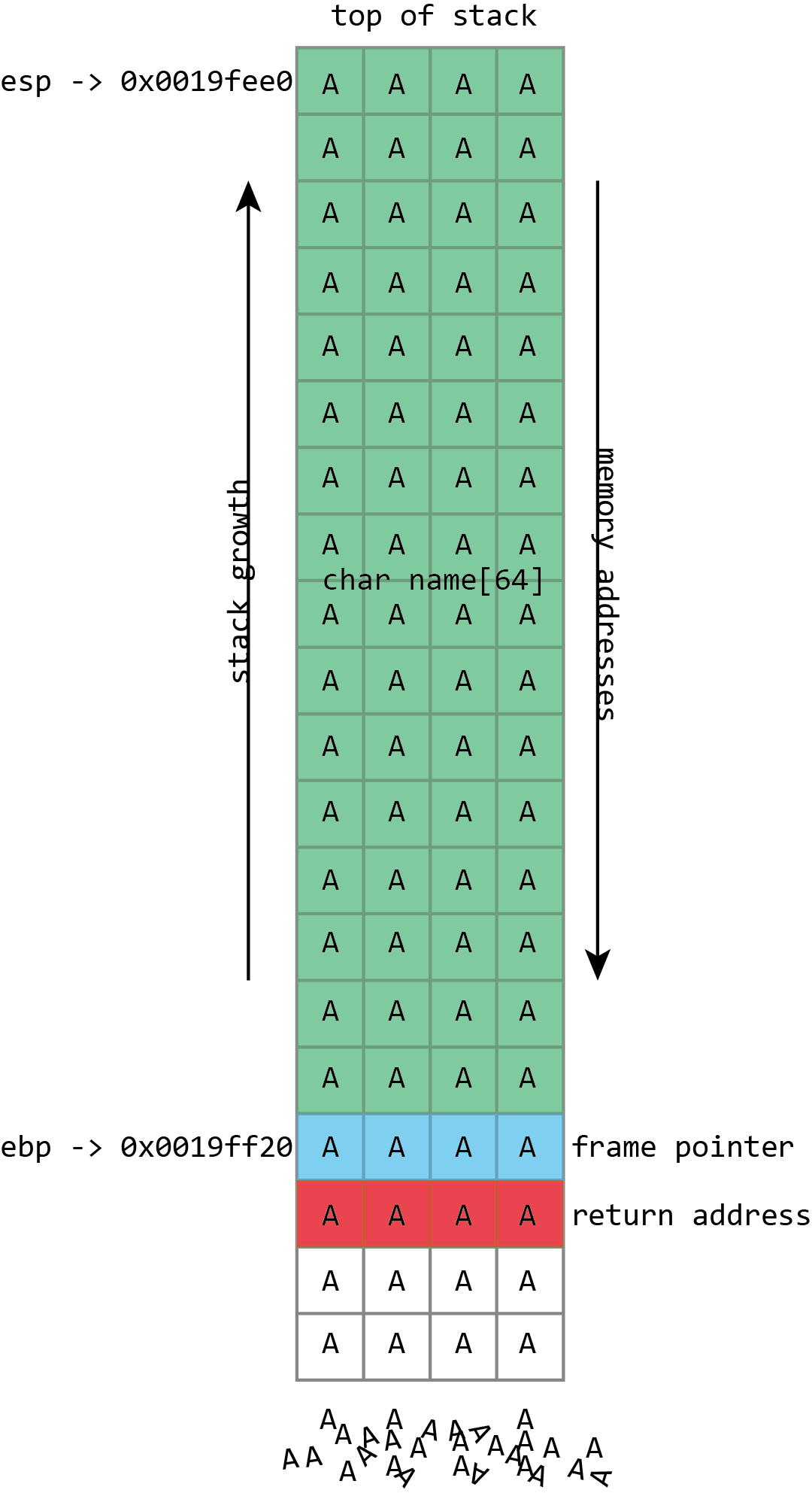
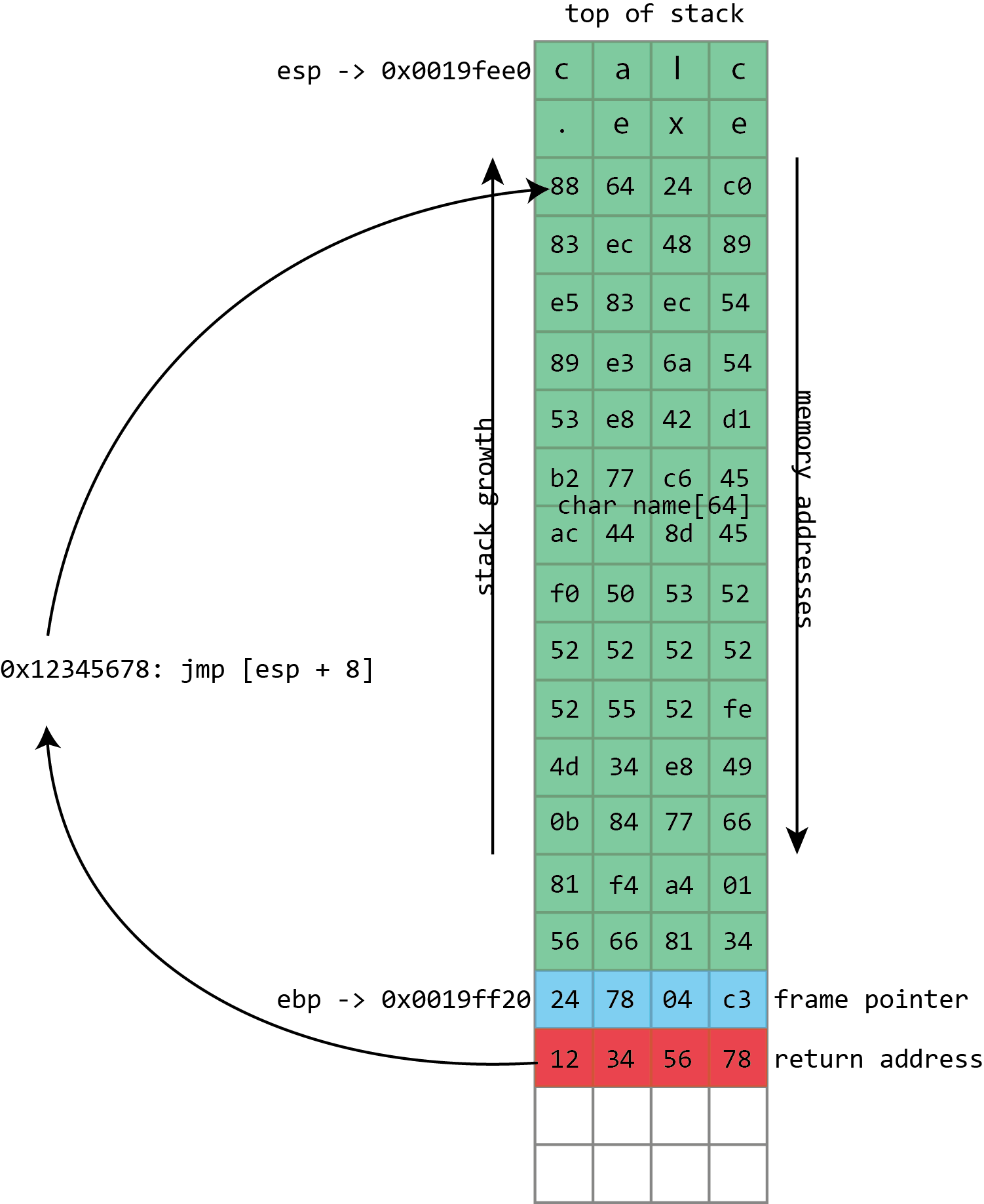
Unfortunately gets() is a really stupid function. If we just hold down A on the keyboard it won’t stop once it’s filled the name buffer. It’ll just keep on writing data to memory, overwriting the frame pointer, the return address, and anything and everything else it can.
name in the above screenshot is the kind of buffer that’s regularly overflowed. Its size is fixed at exactly 64 characters. In this case it’s filled with a bunch of numbers, and it ends in a final null. As should be clear from the above picture, if more than 64 bytes are written into the name buffer, then other values on the stack will be damaged. If four extra bytes are written, the frame pointer will be destroyed. If eight extra bytes are written, both the frame pointer and the return address get overwritten.
Clearly this will lead to damaging the program’s data, but the problem of buffer flows is more serious: they often lead to code execution. This happens because those overflowed buffers won’t just overwrite data. They can also overwrite the other important thing kept on the stack—those return addresses. The return address controls which instructions the processor will execute when it’s finished with the current function; it’s meant to be some location within the calling function, but if it gets overwritten in a buffer overflow, it could point anywhere. If attackers can control the buffer overflow, they can control the return address; if they can control the return address, they can choose what code the processor executes next.
The process probably won’t have some nice, convenient “compromise the machine” function for the attacker to run, but that doesn’t really matter. The same buffer that was used to overwrite the return address can also be used to hold a short snippet of executable code, called shellcode, that will in turn download a malicious executable, or open up a network connection, or do whatever else the attacker fancies.
Traditionally, this was trivial to do because of a trait that may seem a little surprising: generally, each program would use the same memory addresses each time you ran it, even if you rebooted in between. This means that the location of the buffer on the stack would be the same each time, and so the value used to overwrite the return address could be the same each time. An attacker only had to figure out what the address was once, and the attack would work on any computer running the flawed code.
An attacker’s toolkit
In an ideal world—for the attacker, that is—the overwritten return address can simply be the address of the buffer. When the program is reading input from a file or a network, this can often be the case for example.
Other times the attacker has to employ tricks. In functions that process human-readable text, the zero byte (or “null”) is often treated specially; it indicates the end of a string, and the functions used for manipulating strings—copying them, comparing them, combining them—will stop whenever they hit the null character. This means that if the shellcode contains the null character, those routines are liable to break it.
To exploit the overflow, instead of just writing As and smashing everything, the attacker fills the buffer with shellcode: a short piece of executable code that will perform some action of the attacker’s choosing. The return address is then overwritten with an address referring to the buffer, directing the processor to execute the shellcode when it tries to return from a function call.
To handle this, attackers can use various techniques. Pieces of code can convert shellcode that contains null characters into equivalent sequences that avoid the problem byte. They can even handle quite strict restrictions; for example, an exploitable function may only accept input that can be typed on a standard keyboard.
The address of the stack itself often contains a null byte, which is similarly problematic: it means that the return address cannot be directly set to the address of the stack buffer. Sometimes this isn’t a big issue, because some of the functions that are used to fill (and, potentially, overflow) buffers will write a null byte themselves. With some care, they can be used to put the null byte in just the right place to set the return address to that of the stack.
Even when that isn’t possible, this situation can be handled with indirection. The program and all its libraries mean that memory is littered with executable code. Much of this executable code will have an address that’s “safe,” which is to say has no null bytes.
What the attacker has to do is find a usable address that contains an instruction such as x86’s call esp, which treats the value of the stack pointer as the address of a function and begins executing it—a perfect match for a stack buffer that contains the shellcode. The attacker then uses the address of the call esp instruction to overwrite the return address; the processor will take an extra hop through this address but still end up running the shellcode. This technique of bouncing through another address is called “trampolining.”
Sometimes it can be difficult to overwrite the return address with the address of the buffer. To handle this, we can overwrite the return address with the address of a piece of executable code found within the victim program (or its libraries). This fragment of code will transfer execution to the buffer for us.
This works because, again, the program and all its libraries occupy the same memory addresses every time they run—even across reboots and even across different machines. One of the interesting things about this is that the library that provides the trampoline does not need to ever perform a call esp itself. It just needs to offer the two bytes (in this case 0xff and 0xd4) adjacent to each other. They could be part of some other instruction or even a literal number; x86 isn’t very picky about this kind of thing. x86 instructions can be very long (up to 15 bytes!) and can be located at any address. If the processor starts reading an instruction from the middle—from the second byte of a four byte instruction, say—the result can often be interpreted as a completely different, but still valid, instruction. This can make it quite easy to find useful trampolines.
Sometimes, however, the attack can’t set the return address to exactly where it needs to go. Although the memory layout is very similar, it might vary slightly from machine to machine or run to run. For example, the precise location of an exploitable buffer might vary back and forth by a few bytes depending on the system’s name or IP address, or because a minor update to the software has made a very small change. To handle this, it’s useful to be able to specify a return address that’s roughly correct but doesn’t have to be exactly correct.
This can be handled easily through a technique called the “NOP sled.” Instead of writing the shellcode directly into the buffer, the attacker writes a large number of “NOP” instructions (meaning “no-op”; they’re instructions that don’t actually do anything), sometimes hundreds of them, before the real shellcode. To run the shellcode, the attacker only needs to set the return address to somewhere among these NOP instructions. As long as they land within the NOPs, the processor will quickly run through them until it reaches the real shellcode.
Blame C
The core bug that enables these attacks, writing more to a buffer than the buffer has space for, sounds like something that should be simple to avoid. It’s an exaggeration (but only a slight one) to lay the blame entirely on the C programming language and its more or less compatible offshoots, namely C++ and Objective-C. The C language is old, widely used, and essential to our operating systems and software. It’s also appallingly designed, and while all these bugs are avoidable, C does its damnedest to trip up the unwary.
As an example of C’s utter hostility to safe development, consider the function gets(). The gets() function takes one parameter—a buffer—and reads a line of data from standard input (which normally means “the keyboard”), then puts it into the buffer. The observant may have noticed that gets() doesn’t include a parameter for the buffer’s size, and as an amusing quirk of C’s design, there’s no way for gets() to figure out the buffer’s size for itself. And that’s because gets() just doesn’t care: it will read from standard input until the person at the keyboard presses return, then try to cram everything into the buffer, even if the person typed far more than the buffer could ever contain.
This is a function that literally cannot be used safely. Since there’s no way of constraining the amount of text typed at the keyboard, there’s no way of preventing gets() from overflowing the buffer it is passed. The creators of the C standard did soon realize the problem; the 1999 revision to the C specification deprecated gets(), while the 2011 update removed it entirely. But its existence—and occasional usage—is a nice indication of the kind of traps that C will spring on its users.
The Morris worm, the first self-replicating malware that spread across the early Internet in a couple of days in 1988, exploited this function. The BSD 4.3 fingerd program listened for network connections on port 79, the finger port. finger is an ancient Unix program and corresponding network protocol used to see who’s logged in to a remote system. It can be used in two ways; a remote system can be queried to see everyone currently logged in. Alternatively, it can be queried about a specific username, and it will tell you some information about that user.
Whenever a connection was made to the finger daemon, it would read from the network—using gets()—into a 512 byte buffer on the stack. In normal operation, fingerd would then spawn the finger program, passing it the username if there was one. The finger program was the one that did the real work of listing users or providing information about any specific user. fingerd was simply responsible for listening to the network and starting finger appropriately.
Given that the only “real” parameter is a possible username, 512 bytes is plainly a huge buffer. Nobody is likely to have a username anything like that long. But no part of the system actually enforced that constraint because of the use of the awful gets() function. Send more than 512 bytes over the network and fingerd would overflow its buffer. So this is exactly what Robert Morris did: his exploit sent 537 bytes to fingerd (536 bytes of data plus a new-line character, which made gets() stop reading input), overflowing the buffer and overwriting the return address. The return address was set simply to the address of the buffer on the stack.
The Morris worm’s executable payload was simple. It started with 400 NOP instructions, just in case the stack layout was slightly different, followed by a short piece of code. This code spawned the shell, /bin/sh. This is a common choice of attack payload; the fingerd program ran as root, so when it was attacked to run a shell, that shell also ran as root. fingerd was plumbed into the network, taking its “keyboard input” from the network and likewise sending its output back over the network. Both of these features are inherited by the shell executed by the exploit, meaning that the root shell was now usable remotely by the attacker.
While gets() is easy to avoid—in fact, even at the time of the Morris worm, a fixed version of fingerd that didn’t use gets() was available—other parts of C are harder to ignore and no less prone to screw ups. C’s handling of text strings is a common cause of problems. The behavior mentioned previously—stopping at null bytes—comes from C’s string behavior. In C, a string is a sequence of characters, followed by a null byte to terminate the string. C has a range of functions for manipulating these strings. Perhaps the best pair are strcpy(), which copies a string from a source to a destination, and strcat(), which appends a source string to a destination. Neither of these functions has a parameter for the size of the destination buffer. Both will merrily read from their source forever until they reach a null character, filling up the destination and overflowing it without a care in the world.
Even when C’s string handling functions do take a parameter for the buffer size, they can do so in a way that leads to errors and overflows. C offers a pair of siblings to strcat() and strcpy() called strncat() and strncpy(). The extra n in their names denotes that they take a size parameter, of sorts. But n is not, as many naive C programmers believe, the size of the buffer being written to; it is the number of characters from the source to copy. If the source runs out of characters (because a null byte is reached) then strncpy() and strncat() will make up the difference by copying more null bytes to the destination. At no point do the functions ever care about the actual size of the destination.
Unlike gets(), it is possible to use these functions safely; it’s just difficult. C++ and Objective-C both include superior alternatives to C’s functions, making string manipulation much simpler and safer, but they retain the old C capabilities for reasons of backwards compatibility.
Moreover, they retain C’s fundamental weakness: buffers do not know their own size, and the language never validates the reads and writes performed on buffers, allowing them to overflow. This same behavior also led to the recent Heartbleed bug in OpenSSL. That wasn’t an overflow; it was an overread; the C code in OpenSSL tried to read more from a buffer than the buffer contained, leaking sensitive information to the world.
Fixing the leaks
Needless to say, it is not beyond the wit of mankind to develop languages in which reads from and writes to buffers are validated and so can never overflow. Compiled languages such as the Mozilla-backed Rust, safe runtime environments such as Java and .NET, and virtually every scripting language like Python, JavaScript, Lua, Python, and Perl are immune to this problem (although .NET does allow developers to explicitly turn off all the safeguards and open themselves up to this kind of bug once more should they so choose).
That the buffer overflow continues to be a feature of the security landscape is a testament to C’s enduring appeal. This is in no small part due to the significant issue of legacy code. An awful lot of C code still exists, including the kernel of every major operating system and popular libraries such as OpenSSL. Even if developers want to use a safe language such as C#, they may need to depend on a third-party library written in C.
Performance arguments are another reason for C’s continued use, though the wisdom of this approach was always a little unclear. It’s true that compiled C and C++ tend to produce fast executables, and in some situations that matters a great deal. But many of us have processors that spend the vast majority of their time idling; if we could sacrifice, say, ten percent of the performance of our browsers in order to get a cast iron guarantee that buffer overflows—in addition to many other common flaws—were impossible, we might decide that would be a fair trade-off, if only someone were willing to create such a browser.
Nonetheless, C and its friends are here to stay; as such, so are buffer overflows.
Some effort is made to stop the overflow errors before they bite anyone. During development there are tools that can analyze source code and running programs to try to detect dangerous constructs or overflow errors before those bugs ever make their way into shipping software. New tools such as AddressSantizer and older ones such as Valgrind both offer this kind of capability.
However, these tools both require the active involvement of the developer, meaning not all programs use them. Systemic protections that strive to make buffer overflows less dangerous when they do occur can protect a much greater variety of software. In recognition of this, operating system and compiler developers have implemented a number of systems to make exploiting these overflows harder.
Some of these systems are intended to make specific attacker tasks harder. One set of Linux patches made sure that system libraries were all loaded at low addresses to ensure that they contained at least one null byte in their address; this makes it harder to use their addresses in any overflow that uses C string handling.
Other defenses are more general. Many compilers today have some kind of stack protection. A runtime-determined value known as a “canary” is written onto the end of the stack near where the return address is stored. At the end of every function, that value is checked for modification before the return instruction is issued. If the canary value has changed (because it has been overwritten in a buffer overflow) then the program will immediately crash rather than continue.
Perhaps the most important single protection is one variously known as W^X (“write exclusive-or execute”), DEP (“data execution prevention”), NX (“No Xecute”), XD (“eXecute Disable”), EVP (“Enhanced Virus Protection,” a rather peculiar term sometimes used by AMD), XN (“eXecute Never”), and probably more. The principle here is simple. These systems strive to make memory either writeable (suitable for buffers) or executable (suitable for libraries and program code) but not both. Thus, even if an attacker can overflow a buffer and control the return address, the processor will ultimately refuse to execute the shellcode.
Whichever name you use, this is an important technique not least because it comes at essentially no cost. This approach leverages protective measures built into the processor itself as part of the hardware support for virtual memory.
As described before, with virtual memory every process gets its own set of private memory addresses. The operating system and processor together maintain a mapping from virtual addresses to something else; sometimes a virtual address corresponds to a physical memory address, sometimes it corresponds to a portion of a file on disk, and sometimes it corresponds to nothing at all because it has not been allocated. This mapping is granular, typically using 4,096 byte chunks called pages.
The data structures used to store the mapping don’t just include the location (physical memory, disk, nowhere) of each page; they also contain (usually) three bits defining the page’s protection: whether the page is readable, whether it is writeable, and whether it is executable. With this protection, areas of the process’ memory that are used for data, such as the stack, can be marked as readable and writeable but not executable. Conversely, areas such as the program’s executable code and libraries can be marked as readable and executable but not writeable.
One of the great things about NX is that it can be applied to existing programs retroactively just by updating the operating system to one that supports it. Occasionally programs do run into problems. Just-in-time compilers, used for things like Java and .NET, generate executable code in memory at runtime, and as such need memory that is both writeable and executable (though strictly, they don’t need it to be both things simultaneously). In the days before NX, any memory that was readable was also executable, so these JIT compilers never had to do anything special to their read-writeable buffers. With NX, they need to make sure to change the memory protection from read-write to read-execute.
The need for something like NX was clear, especially for Microsoft. In the early 2000s, a pair of worms showed that the company had some serious code security problems: Code Red, which infected as many as 359,000 Windows 2000 systems running Microsoft’s IIS Web server in July 2001, and SQL Slammer, which infected more than 75,000 systems running Microsoft’s SQL Server database in January 2003. These were high-profile embarrassments.
Both of them exploited stack buffer overflows, and strikingly, though they came 13 and 15 years after the Morris worm, the method of exploitation was virtually identical. An exploit payload was placed into the buffer on the stack and the return address overwritten to execute it. (The only slight nuance was that both of these used the trampoline technique. Instead of setting the return address directly to the address of the stack, they set the return address to an instruction that in turn passes execution to the stack.)
Naturally, these worms were also advanced in other ways. Code Red’s payload didn’t just self-replicate; it also defaced webpages and attempted to perform denial of service attacks. SQL Slammer packed everything it needed to find new machines to exploit and spread through a network in just a few hundred bytes, and it left no footprint on machines it infected; reboot and it was gone. Both worms also worked on an Internet that was enormously larger than the one the Morris worm worked with, and hence they infected many more machines.
But the central issue, that of a straightforwardly exploitable stack buffer overflow, was an old one. These worms were both major news and made many people question the use of Windows in any kind of an Internet-facing, server capacity. Microsoft’s response was to start taking security seriously. Windows XP Service Pack 2 was the first real product with this mindset. It utilized a number of software changes, including a software firewall, changes to Internet Explorer to prevent silent installation of toolbars, plugins—and NX support.
Hardware supporting NX has been mainstream since 2004, when Intel introduced the Prescott Pentium 4, and operating system support for NX has been widespread since Windows XP Service Pack 2. Windows 8 forced the issue even more by cutting off support for older processors that didn’t have NX hardware.
Beyond NX
In spite of the spread of NX support, buffer overflows remain a security issue to this day. That’s because a number of techniques were devised to bypass NX.
The first of these was similar to the trampolining trick already described to pass control to the shellcode in a stack buffer via an instruction found in another library or executable. Instead of looking for a fragment of executable code that will pass execution directly back to the stack, the attacker looks for a fragment that does something useful in its own right.
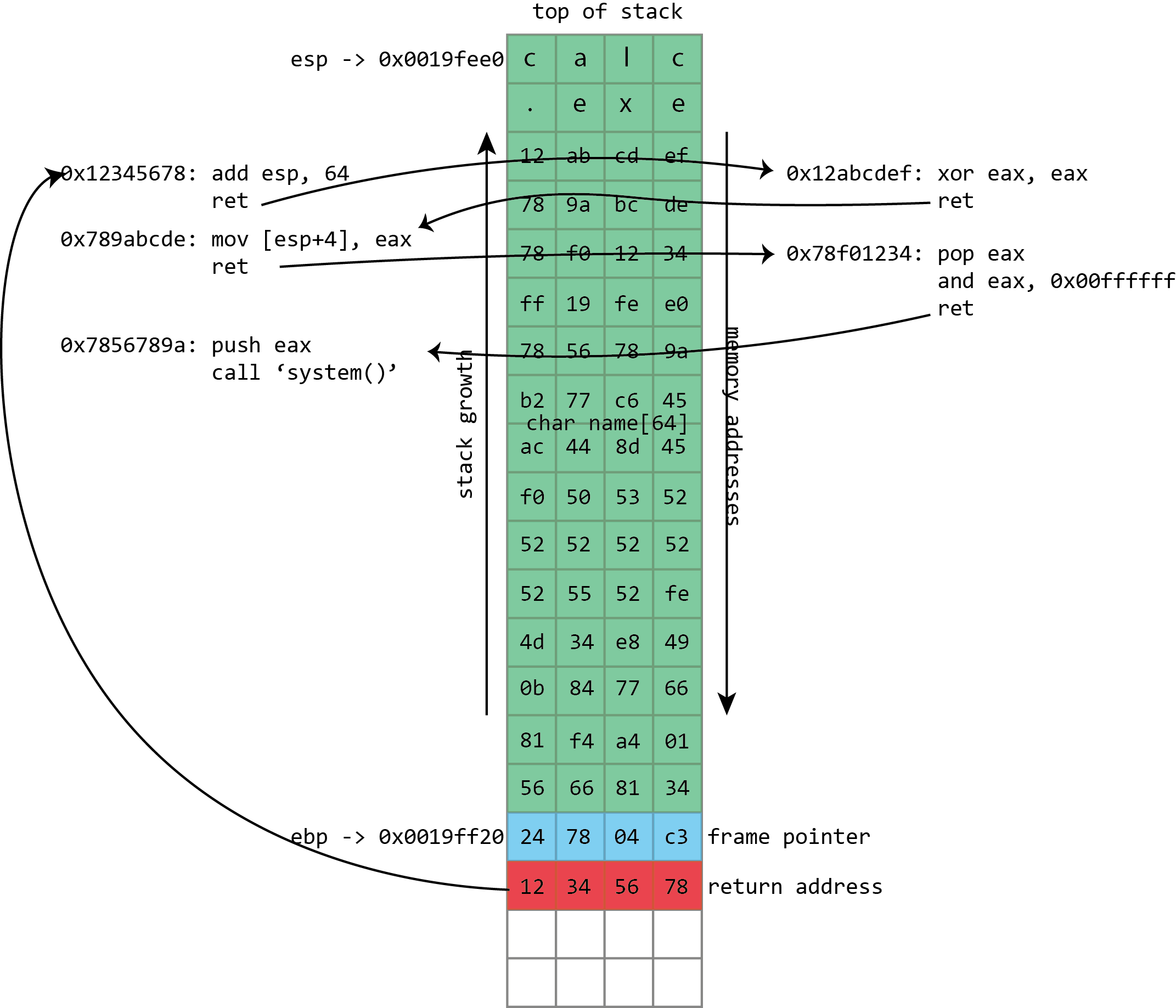
Perhaps the best candidate for this is the Unix system() function. system() takes one parameter: the address of a string representing a command line to be executed, and traditionally that parameter is passed on the stack. The attacker can create a command-line string and put it in the buffer to be overflowed, and because (traditionally) things didn’t move around in memory, the address of that string would be known and could be put on the stack as part of the attack. The overwritten return address in this situation isn’t set to the address of the buffer; it’s set to the address of the system() function. When the function with the buffer overflow finishes, instead of returning to its caller, it runs the system() function to execute a command of the attacker’s choosing.
This neatly bypasses NX. The system() function, being part of a system library, is already executable. The exploit doesn’t have to execute code from the stack; it just has to read the command line from the stack. This technique is called “return-to-libc” and was invented in 1997 by Russian computer security expert Solar Designer. (libc is the name of the Unix library that implements many key functions, including system(), and is typically found loaded into every single Unix process, so it makes a good target for this kind of thing.)
While useful, this technique can be somewhat limited. Often functions don’t take their arguments from the stack; they expect them to be passed in registers. Passing in command-line strings to execute is nice, but it often involves those annoying nulls, which can foul everything up. Moreover, it makes chaining multiple function calls very difficult. It can be done—provide multiple return addresses instead of one—but there’s no provision for changing the order of arguments, using return values, or anything else.
Instead of filling the buffer with shellcode, we fill it with a sequence of return addresses and data. These return addresses pass control to existing fragments of executable code within the victim program and its libraries. Each fragment of code performs an operation and then returns, passing control to the next return address.
Over the years, return-to-libc was generalized to alleviate these restrictions. In late 2001, a number of ways to extend return-to-libc to make multiple function calls was documented, along with solutions for the null byte problem. These techniques were nonetheless limited. A more complicated technique formally described in 2007 for the most part lifted all these restrictions: return-oriented-programming (ROP).
This used the same principle as from return-to-libc and trampolining but generalized further still. Where trampolining uses a single fragment of code to pass execution to shellcode in a buffer, ROP uses lots of fragments of code, called “gadgets” in the original ROP paper. Each gadget follows a particular pattern: it performs some operation (putting a value in a register, writing to memory, adding two registers, etc.) followed by a return instruction. The same property that makes x86 good for trampolining works here too; the system libraries loaded into a process contain many hundreds of sequences that can be interpreted as “perform an action, then return” and hence can be used in ROP-based attacks.
The gadgets are all chained together by a long sequence of return addresses (and any useful or necessary data) written to the stack as part of the buffer overflow. The return instructions leap from gadget to gadget with the processor rarely or never calling functions, only ever returning from them. Remarkably, it was discovered that, at least on x86, the number and variety of useful gadgets is such that an attacker can generally do anything; this weird subset of x86, used in a peculiar way, is often Turing complete (though the exact range of capabilities will depend on which libraries a given program has loaded and hence which gadgets are available).
As with return-to-libc, all the actual executable code is taken from system libraries, and so NX protection is useless. The greater flexibility of the approach means that exploits can do the things that are difficult even with chained return-to-libc, such as calling functions that take arguments in registers, using return values from one function as an argument for another, and much more besides.
The ROP payloads vary. Sometimes they’re simple “create a shell”-style code. Another common option is to use ROP to call a system function to change the NX state of a page of memory, flipping it from being writable to being executable. Doing this, an attacker can use a conventional, non-ROP payload, using ROP only to make the non-ROP payload executable.
Getting random
This weakness of NX has long been recognized, and a recurring theme runs throughout all these exploits: the attacker knows the memory addresses of the stack and system libraries ahead of time. Everything is contingent on this knowledge, so an obvious thing to try is removing that knowledge. This is what Address Space Layout Randomization (ASLR) does: it randomizes the position of the stack and the in-memory location of libraries and executables. Typically these will change either every time a program is run, every time a system is booted, or some combination of the two.
This greatly increases the difficulty of exploitation, because all of a sudden, the attacker doesn’t know where the ROP instruction fragments will be in memory, or even where the overflowed stack buffer will be.
ASLR in many ways goes hand in hand with NX, because it shores up the big return-to-libc and return-oriented-programming gaps that NX leaves. Unfortunately, it’s a bit more intrusive than NX. Except for JIT compilers and a few other unusual things, NX could be safely added to existing programs. ASLR is more problematic; programs and libraries need to ensure that they do not make any assumptions about the address they’re loaded at.
On Windows, for example, this shouldn’t be a huge issue for DLLs. DLLs on Windows have always supported being loaded at different addresses, but it could be an issue for EXEs. Before ASLR, EXEs would always be loaded at an address of 0x0040000 and could safely make assumptions on that basis. After ASLR, that’s no longer the case. To make sure that there won’t be any problems, Windows by default requires executables to indicate that they specifically support ASLR and opt in to enabling it. The security conscious can, however, force Windows to enable it for all executables and libraries even if programs don’t indicate that they support it. This is almost always fine.
The situation is perhaps worse on x86 Linux, as the approach used for ASLR on that platform exacts a performance cost that may be as high as 26 percent. Moreover, this approach absolutely requires executables and libraries to be compiled with ASLR support. There’s no way for an administrator to mandate the use of ASLR as there is in Windows. (x64 does not quite eliminate the performance cost of the Linux approach, but it does greatly alleviate it.)
When ASLR is enabled, it provides a great deal of protection against easy exploitation. ASLR still isn’t perfect, however. For example, one restriction is the amount of randomness it can provide. This is especially acute on 32-bit systems. Although the memory space has more than 4 billion different addresses, not all of those addresses are available for loading libraries or placing the stack.
Instead, it’s subject to various constraints. Some of these are broad goals. Generally, the operating system likes to keep libraries loaded fairly close together at one end of the process’ address space, so that as much contiguous empty space is available to the application as possible. You wouldn’t want to have one library loaded every 256MB throughout the memory space, because the biggest single allocation you’d be able to make would be a little less than 256MB, which limits the ability of applications to work on big datasets.
Executables and libraries generally have to be loaded so that they start on, at the very least, a page boundary. Normally, this means they must be loaded at an address that’s a multiple of 4,096. Platforms can have similar conventions for the stack; Linux, for example, starts the stack on a multiple of 16 bytes. Systems under memory stress sometimes have to further reduce the randomness in order to fit everything in.
The impact of this varies, but it means that attackers can sometimes guess what an address will be and have a reasonable probability of guessing right. Even a fairly low chance—one in 256, say—can be enough in some situations. When attacking a Web server that will automatically restart crashed processes, it may not matter that 255 out of 256 attacks crash the server. It will simply be restarted, and the attacker can try again.
But on 64-bit systems, there’s so much address space that this kind of guessing approach is untenable. The attacker could be stuck with a one in a million or one in a billion chance of getting it right, and that’s a small enough chance as to not matter.
Guessing and crashing isn’t much good for attacks on, say, browsers; no user is going to restart a browser 256 times in a row just so that an attacker can strike it lucky. As a result, exploiting this kind of flaw on a system with both NX and ASLR can’t be done without help.
This help can come in many forms. One route in browsers is to use JavaScript or Flash—both of which contain JIT compilers that generate executable code—to fill large portions of memory with carefully constructed executable code. This produces a kind of large-scale NOP sled in a technique known as “heap spraying.” Another approach is to find a secondary bug that inadvertently reveals memory addresses of libraries or of the stack, giving the attacker enough information to construct a custom set of ROP return addresses.
A third approach was again common in browsers: take advantage of libraries that don’t use ASLR. Old versions of, for example, Adobe’s PDF plugin or Microsoft’s Office browser plugins didn’t enable ASLR, and Windows by default doesn’t force ASLR on non-ASLR code. If attackers could force such a library to load (by, for example, loading a PDF into a hidden browser frame) then they no longer needed to be too concerned about ASLR; they could just use that non-ASLR library for their ROP payload.
A never-ending war
The world of exploitation and mitigation techniques is one of cat and mouse. Powerful protective systems such as ASLR and NX raise the bar for taking advantage of flaws and together have put the days of the simple stack buffer overflow behind us, but smart attackers can still combine multiple flaws to defeat these protections.
The escalation continues. Microsoft’s EMET (“Enhanced Mitigation Experience Toolkit”) includes a range of semi-experimental protections that try to detect heap spraying or attempts to call certain critical functions in ROP-based exploits. But in the continuing digital arms war, even these have security techniques that have been defeated. This doesn’t make them useless—the difficulty (and hence cost) of exploiting flaws goes up with each new mitigation technique—but it’s a reminder of the need for constant vigilance.
Thanks to Melissa Elliott for her invaluable feedback.
Social media may get credit for things it doesn’t deserve (and criticized for problems it didn’t cause), but few can argue that without social media, there would be no such thing as citizen journalism.
Only a decade ago, the idea of general public news was somewhat absurd. Media was the media, and outside of the opinion page or comments sections, we simply didn’t participate. Blogs dotted the online landscape, but to the general public they were mostly a novelty and often viewed with a bit of mirth. What did these tech savvy upstart young-lings know about the world?
The catch was that blogs were quickly gaining traction not as the outlet for emotional youth, but sounding points for well informed, and in some cases even additional outputs from news organizations themselves.
Today the blog has fallen away as a news source, replaced by micro blogging and main stream social applications. As always, with any change there are benefits and pitfalls. Let’s look at a few…
Accountability
Accountability flows both ways does it not? Big brother is always watching – but in a slightly ironic and perhaps scarier twist, little brother is watching too. Few incidents or mistakes on mainstream media’s part will escape a public eye armed with smart devices.
But little brother’s sudden power comes with a dark side – with no motivation outside fame, and no recourse for damage, the once harmless busybody is now a potential social media fallout in the works for anyone unlucky to be caught in their cross-hairs. This is a stark contrast to mainstream media which must carefully temper itself to avoid litigation and other forms of backlash.
Accuracy
As with accountability, citizen journalism is a double edged sword. Cameras don’t lie, but they DO distort. Little brother’s vigil over mainstream media may force a more mediated approach to journalism, though thus far it seems to have resulted in quantity over quality.
The same cannot be said for the citizen journalism itself. Little brother operates without training or research, resulting in news that is raw, but may not tell the entire story at all. Just as with mainstream media and its own inevitable bias, it is up to the consumer to think critically and disseminate material with an informed and emotionally detached eye.
Previously (several times actually) I had postulated that social media can be a dangerous lure for the unprepared. Like a great sponge, it has the power to absorb, deflect, and ultimately destroy movements before they even get started.
With that said, it’s fair to say most grass roots movements cannot survive without social media behind them. So how then do movements maintain this precarious balance? Let’s look at some possible counteraction against social media pitfalls.
Issues
Pseudo Participation
This has been cited many times throughout DC Current, but for posterity, I refer to the ease would be volunteers or other audience members fool themselves into a sense of participation. Click a like, type a quick comment, maybe even argue with a critic in some round robin debate for a while, and that person walks away with a sense of accomplishment. The problem of course is they haven’t actually done anything tangible to assist your cause.
A possible technique to counter this problem is replacing general calls for participation and emotional appeals with specific needs. As an example, a homeless shelter could post an interactive calendar that indicates times of need and allows users to click these “blank” areas to schedule themselves. The single click convenience is still present, but is being harnessed into a real world action. Similar techniques could be employed for political movements – keeping a steady stream of polite but purposeful calls to a political figure’s channels over months might prove more effective then shouting them down for a few days until your volunteer momentum is lost.
Emotional Drive
Emotions are a powerful motivator, but are often fleeting. Appealing to emotions with your movement might get things off to a great start, but sooner or later someone else will have a catchy new slogan or cause that drains away attention and resources from yours.
This is where balance and using your voice to incite real movement comes into play. Obviously a bit of emotional appeal is needed, but once you have an audience, it’s time to focus on what that audience can accomplish besides growing until it bursts and evaporates.
Research your movement carefully before you “go live”. Find out exact what voluntary steps you can take. Do you want to build houses? Evoke political change? Send care packages overseas? Whatever the cause, someone has likely done something similar and there are channels or actions to assist you. This incidentally, is where social media can help – remember, it’s not just a soapbox, but a powerful education tool as well.
After having mastered your techniques to a satisfactory level, this is when you switch to the soapbox mode. The social media is now now just a way to get attention, but a tool to instruct your audience on what exactly they need to do for real change. You may also be surprised at how quickly the effect snowballs, as audience members will bring their own skills perfectly suited for allotted tasks, which can then be spread back out through the social media in a beautiful cycle.
Social media is touted as the ultimate tool for movements, and it may well be. Where else can a group with no money, no voice otherwise, and no access to influence in the system go to advocate change?
The answer is quite a few actually. No offense to Mr. Khan or Keller, but social media is a tool, not the end all be all of grass roots movements.
Questions
Q1. What has social media accomplished?
One example given by Mr. Keller and Douglas is the WTO meetings in Seattle, and how social media enabled the organization of protest movements.
Beginning with the 18 June 1999 ‘Carnival Against Capital!’ demonstration that covertly organized hundreds of thousands of protesters (including labor, environmentalist, feminist, anti-capitalist, animal rights, anarchist, and other groups) throughout the world to demonstrate in new found solidarity, the Carnival continued with the infamous ‘Battle for Seattle’ against the World Trade Organization (WTO) meeting in December 1999. Thus, an international protest movement surfaced in resistance to neo-liberal institutions and their related globalization policies, while democracy, social justice, and a better world were championed.
What does not get mentioned is the protests were by and large ignored, and the WTO continues to operate unfettered. Bluster and noise, now a forgotten footnote in obscure writings. As is also the case for IRAQ war protests also mentioned in the article.
Does that sound familiar? How many “movements” have started on social media, made some noise, and peter out within months.
Conversely, women’s suffrage, prohibition, removal of prohibition, civil rights, are all powerful examples of grass root movements that DID affect change, and did so without the benefit of electronic media.
Social media can claim accomplishments to a degree, but comparatively speaking, it is a drop in the historical bucket.
Q2. How to truly empower social media?
If we can assume Q1 is correct, then the next question must be why? Ease of use might be one common reason. Successful grass root movements actually require grass roots level effort. Posting on social media and waving signs aren’t going to frighten the establishment any time soon.
Use of social media to organize practical change can. For instance, in lieu of emotional slogans and zerg rush post movements that will be ignored and forgotten, a movement might instead try to educate their target audience. Explain the issue, and provide channels the audience may use (numbers to representatives, company meetings, donation targets, etc.). In general, keeping in mind the social media is a tool and not an end will pay dividends.
With all of the hoopla that surrounds the rise of social media, it is often easy to overstate the effect it has on various aspects of our lives. But there is one area where it may be difficult not to understate social media’s influence, and that is the news. To be short, social media has not merely influenced the news, it has become the news. Let’s brooch some discussion topics this phenomenon and responses to it.
Interactivity
Not more then a decade ago, news sources were many, but not varied, as they all used the same “them to you” model. Be it radio, paper, cable, or just your local at 11, the public had very little input aside from editorials or the occasional gimmick dial in.
Social media has rewritten the rules on interaction. A news article found online is now subject the immediate dissemination and discussion – with results that are not always pretty. In response, some organizations have chosen to close their topic forums or comment services, but this is no defense. Users simply link the article to their favorite social media application and the discussion proceeds unfettered.
With this in find, news outlets have been forced to rethink their publicity policies, as even the slightest mistake (or perception of one) can have disastrous consequences.
That all said, interactivity is also a boon for organizations, as they can leverage this to create a sense of responsiveness to their communities, and gain another source for their story searches.
Economy
Smaller news sources with little market and even less in their budgets have found social media to be a powerful and money saving tool. Facebook live streaming for instance, allows video distribution without networks or even a studio. The social media itself then acts as a distribution tool, again affording smaller news outlets a larger voice with little investment.
Quality
An oft cited complaint is the downward turn in news quality due to social media. This may be a fair complaint. Placing power of voice into the hands of individuals who lack the training, professionalism, or accountability of a larger organization, and mixing that with sometimes emotionally charged topics is a recipe for muck.
Then comes the “right now” > “right” issue. With instant access being order of the day, there is simply no time for prudent quality control. Throw in click bait, fake news, and other intentionally misuses of news media and there is a good chance of generating complete public apathy. It’s still too early to see how these problems will be resolved, but hope springs eternal. it’s not the first time news delivery has been disrupted, and perhaps as the social media concept matures, quality will come along for the ride.
If if a picture paints a thousand words, then a typical video paints 60,000 words a minute. Virtually any organization can be served by an occasional video displaying its product in action, and this is especially true for Non-Profits. By way of recording the non-profit’s charitable work in action, the non-profit entity may well find itself invoking the emotional response needed to garner greater support from volunteers and the general public alike.
Recording a large scale task,such as home building, then editing to a time lapse.
Allowing volunteers to post short clips to a central account.
Live streaming or blogging by non-profit leaders.
The requirements for video uploading are remarkably within reach. Time lapsed, or other special effects are still the province of desktop software and some technical know how, but otherwise all one needs is an account to one of several video compatible applications and a smart phone.
Top Down Sharing
One of the issues facing non-profits attempting to navigate social media is the sheer myriad of options. At any given time there will be ~10 social media applications with relevant world wide saturation (assuming the English speaking world). Choosing which can be a daunting task, especially considering how quickly a freshly adopted presence may quickly be replaced be something newer.
A possible solution is the top down sharing approach. Many social media applications offer the ability to automatically share to each other, and still others may work with websites by offering feed portals. For instance, consider the following:
Instagram allows direct sharing to Twitter & Facebook when a port is created.
Twitter offers automatic sharing to Facebook whenever tweets are created, and also offers users a predefined window feed for websites.
Most CMS systems offer auto share to Twitter, Facebook, and most other social applications.
What this means is that an entity with Instagram, Facebook, Twitter, a website and very little time to manage all of them would be best serve with a compromise:
Set up Twitter to auto share to Facebook.
Leverage Twitter’s feed feature for the website.
All photographic posts are performed through Instagram and auto shared to Twitter. Twitter in turn auto shares to Facebook and appears in the website feed.
Short, non photographic messages are routed directly through twitter. Facebook is reserved for longer posts, and the website for informational articles.
Start The Press
Before the advent of social media applications, a website was the starting point for most entities seeking an online presence. Because of the greater amount of front end effort (or cost), some entities now opt to make their website secondary or in some cases never bother at all. While this is understandable, it is a very serious mistake. A website offers several advantages over social media applications.
No Advertisements – Unless you are using a free service to host, your website is yours alone, and you don’t have to worry about another entity inserting itself right between your lines.
Content control – websites give you full control not just of what goes in, but how it looks. Colors and logos are often a big part of an organization’s brand. Only a website offers this freedom.
Permanence – Websites are the little black dress of the internet. They may not be fashion forward, but they maintain a steady relevance . Conversely, the hottest social media applications today may well be abandoned or even shut down in short notice.
Centralization – Rather than compete with social networks, a well crafted website works with them, serving as both a portal to social applications and a funneling target for social media users.
All of these advantages do come at a price. Websites require a high level of maintenance – uploading an electronic billboard and expecting any sort of positive result is pure folly. The website must have some interactive content, or at least (as above) serve as a portal to social media apps that do. Furthermore the website must be updated with some level of frequency to avoid becoming stale. Most organizations simply do not have the time or expertise for such tasks.
To help mitigate website maintenance, a powerful solution is to employ Content Management Systems. WordPress is the most oft used example. Drupal, SMS, and others offer similar solutions. Content Managed Sites offer end users the ability to edit content (hence the name) without editing the site itself, essentially separating the content from its engine. In short – modifying the content becomes akin to creating a Word Documents or PowerPoint. Users can upload media, pictures, link to social media sites, and even make minor design changes depending upon their level of comfort.
Advanced design aspects are still the province of information systems professionals, but by employing a CMS, you don’t need to call your IT guy just to write up a manifest on latest charity excursion.
Initialization
For most non academic non profit organizations, WordPress is highly recommended over other content management systems simply because of the wide array of support tools and general ubiquity. Organizations need not even host the WordPress application or own their own domain name, though at minimum the later is highly recommended. In the case where an entity prefers not to host their own application, WordPress.com is a general maintenance and cost free alternative.
A disadvantage of CMS, WordPress included is lack of individual design. A WordPress site’s presentation is controlled by themes, which can be selected from a large variety of free items, designed by the user, or professionally created. Each has its own advantages and shortcomings.
Free Themes
Free themes are by far the easiest and least time consuming choice. Simply select from one of hundreds of predefined themes and with a single click and your site is operational. Many of the available themes sport impressive features, responsive design (mobile compatibility), and a very professional look.
Free themes do have the disadvantage of having no customization tailored to your organization. Furthermore it is quite likely the most visually appealing and functional are already in use by many other organizations, meaning your site may have sport a very common theme. Most free themes do include options for basic attributes (colors, graphics, etc.), albeit not quite enough to offset identical basic designs.
Professional Themes
Outsourced theme building is essentially the same concept as professional site building, with the exception that only the visual style is being coded and deployed – not the website engine. The obvious advantage over a free theme harnessing technical and design expertise of a dedicated firm to create a unique visual look for your organization’s site.
Expense is consideration of course, but as the contract is for visual design only costs are considerably less than a full site design. Moreover, there are multiple online only micro development groups dedicated only to WordPress design, offering extremely competitive contracted rates.
In House Themes
The final option available is to develop themes and options in house. This can be a good option when technical expertise is available within the organization. It may not be practical to field a dedicated technology staff, but harnessing technically capable personnel on a temporary basis until builds are complete may be a tenable alternative.
It’s no secret that an online presence is all but a necessity for any organization to survive, or at least remain relevant in the first world. Unfortunately being “online” isn’t enough. The internet is a vast, unwieldy beast, and it does take some planning to make it work for you. Get it right though, and you’ve just armed yourself with the second best tool any entity could ask for (the best still being a compelling product, natch).
Non-Profits are no exception, it just so happens the product is their mission. Want to promote that mission and or gather resources to execute it? Look to the money makers and learn from them.
Discussion
Websites
Before the advent of social media applications, a website was the starting point for most entities seeking an online presence. Because of the greater amount of front end effort (or cost), some entities now opt to make their website secondary or in some cases never bother at all. While this is understandable, it is a very serious mistake. A website offers several advantages over social media applications.
No Advertisements – Unless you are using a free service to host, your website is yours alone, and you don’t have to worry about another entity inserting itself right between your lines.
Content control – websites give you full control not just of what goes in, but how it looks. Colors and logos are often a big part of an organization’s brand. Only a website offers this freedom.
Permanence – Websites are the little black dress of the internet. They may not be fashion forward, but they maintain a steady relevance . Conversely, the hottest social media applications today may well be abandoned or even shut down in short notice.
Centralization – Rather than compete with social networks, a well crafted website works with them, serving as both a portal to social applications and a funneling target for social media users.
All of these advantages do come at a price. Websites require a high level of maintenance – uploading an electronic billboard and expecting any sort of positive result is pure folly. The website must have some interactive content, or at least (as above) serve as a portal to social media apps that do. Furthermore the website must be updated with some level of frequency to avoid becoming stale. Most organizations simply do not have the time or expertise for such tasks.
To help mitigate website maintenance, a powerful solution is to employ Content Management Systems. WordPress is the most oft used example – this site for instance is powered by WordPress. Drupal, SMS, and others offer similar solutions. Content Managed Sites offer end users the ability to edit content (hence the name) without editing the site itself, essentially separating the content from its engine. In short – modifying the content becomes akin to creating a Word Documents or PowerPoint. Users can upload media, pictures, link to social media sites, and even make minor design changes depending upon their level of comfort.
Advanced design aspects are still the province of information systems professionals, but by employing a CMS, you don’t need to call your IT guy just to write up a manifest on latest charity excursion.
Social Media
The game changer. In theory. To an organization long on needs and short on resources, social media beckons like an old lover, and has just as many pitfalls.
Wide Reach – The potential for social media to reach an audience can be more or less described as “everyone online”. Realistically, that’s not likely, but even today advertisers understand word of mouth is the best for of ad. Social media is the ultimate tool for jump-starting a virtual word of mouth.
Ease of use – Few people have the expertise or desire to build and edit a working website, and few non profits have the funding to pay someone who does. Even with CMS, a website simply cannot hope to compete with the single click ease of social media posting.
Instant Communication – Websites may employ forums for two way discussion, but for instant interaction with customers and constituents, social media is the king.
Front Lines – The advantage of websites are their “slow and steady”, never going completely out of style approach. But for entities looking to grab attention fast, sometimes it pays to follow the fad.
Cost effectiveness – Social media applications and websites like may be used as fundraisers, but only social media applications are “free”. It costs nothing but time to log into an social media app and create a presence.
Doesn’t that look like a great deal? Just be careful. If not leveraged correctly, social media will happily serve as a detriment to your cause or organization. One of the biggest pitfalls is simply not keeping social content up to date. Whereas a website can get away with monthly updates, a social media site must update at least twice a week.
Worse, a website left to rot is simply ignored or perhaps assumed by viewers the information did not need updating. An out of date social media presence implies the organization is closed, too short handed to carry out their mission, or simply doesn’t care. In effect, the organization would have been better off not to use social media t all.
Another issue may simply be the overwhelming number of options. At any given time there will be ~10 social media applications with relevant world wide saturation (assuming the English speaking world). Choosing which can be a daunting task, especially considering how quickly a freshly adopted presence may quickly be replaced be something newer.
A possible solution is the top down sharing approach. Many social media applications offer the ability to automatically share to each other, and still others may work with websites by offering feed portals. For instance, consider the following:
Instagram allows direct sharing to Twitter & Facebook when a port is created.
Twitter offers automatic sharing to Facebook whenever tweets are created, and also offers users a predefined window feed for websites.
Most CMS systems offer auto share to twitter, Facebook, and most other social applications.
What this means is that an entity with Instagram, Facebook, Twitter, a website and very little time to manage all of them would be best serve with a compromise:
Set up Twitter to auto share to Facebook.
Leverage Twitter’s feed feature for the website.
All photographic posts are performed through Instagram and auto shared to Twitter. Twitter in turn auto shares to Facebook and appears in the website feed.
Short, non photographic messages are routed directly through twitter. Facebook is reserved for longer posts, and the website for informational articles.
Using this approach, the user is only every dealing with one application at a time – usually Instagram, but keeps two other social applications and their website flush with fresh content.
Conclusion
Leveraging the internet is not easy, but you need not pour vast amounts of time and money into creating a presence. With a bit of resourcefulness and a great cause or product, one can quickly make themselves a force to be reckoned with in the online world.
In some ways the digital divide makes a fine example, albeit a very unfortunate one, of the Square Cube Law. It’s not simply that the digital divide itself is growing exponentially, but the rate at which commerce depends upon electronic networking climbs at a similar clip.
We in the first world have a responsibility to take on this gap, if not for altruistic purposes, then for our own benefit. As more and more of the populace becomes disenfranchised, they in turn cannot contribute to culture, physical needs, and commerce. Sooner or later we will all suffer the loss.
Discussion
Several solutions to attacking the digital divide are being tested and applied with varying degrees of success. All have their advantages and challenges.
Physical Connections
Usually when the digital divide is mentioned, the idea of having no physical connection springs to mind, and with good reason. Oft repeated elsewhere in my articles is that only ~40% of the world is online at all. Of that 40%, very few enjoy a quality of connection we take for granted.
On the surface this is an easy problem to solve. String some fiber optic, fire up an access point or two and everyone is connected, and there is some truth to this. Infrastructure is the first step to a connected society.
There are however a few challenges.
Infrastructure
What infrastructure is best suited? Satellite connections might work well in the highlands of Nepal where the open shy is plentiful and wired infrastructure is prone to destruction by the unpredictable Himalayan wind shear – but the same concept would be virtually useless in the thick canopy of South America’s rain forests.
Contact Point
Once connectivity groundwork is laid out, how do you actually connect the people living next to it? A few WIFI access points might have the capacity to cover an entire village, but what good is that when no one owns a phone? Place a phone in everyone’s hands? How long can they be expected to last in a harsh environment where the most basic human needs are sometimes a privilege?
A more prudent solution might be something akin to an internet cafe, where centralized maintenance can take place, but this again does little to connect individuals on an every day basis.
Virtual Connections
By virtual, I’m not talking about a failed GameBoy offshoot from the early 90’s. There is more to being connected than having a wire and a computer. The to us perfunctory skill of operating and maintaining electronic equipment is mythical to most of the world. Typing, searching, installing software, and understanding search heuristics on the most basic level are all skills that are necessary for an online world to be anything beyond a curious novelty.
Is it realistic to expect we can educate the entire world at the same rate we run wires into their territory? If not, how do we open up the online world to people not equipped to use it while offering the level of power that we in the first world enjoy?
Follow The Money
The final challenge is one that sees little discussion, but may pose the greatest danger to a connected, free society. I’ve barely skimmed the surface of approaches and pitfalls when attempting to connect the world, but it is obvious to anyone no matter what approach is used, that approach will be costly.
The danger though is not one o lacking funds (though of course that is a problem). It is one of power. SOMEONE is paying for the “free” WIFI in your neighborhood or a fr away country. It might be you through taxes, a Non-Profit, or some mega corp looking for publicity. In any case, the purse holds the power, and by ceding the responsibility of connection to another entity, one cedes control.
We in the first world still have a choice of how we choose to connect. Even in monopolized areas we have some (however infinitesimal) power since we are direct customers. Third world areas have no such privilege. It might not hurt to take a long look at the long term ramifications and motivations of a single entity trying to connect X territory.
Conclusion
Lots of negativity, yes? It’s only caution – we can and should push to connect the world, but in doing so avoid being dogmatic. No solution is perfect. Instead a multifaceted, careful approach based on the needs of culture, environment, and economic realities should be taken. In short, crossing the digital divide is a marathon, not a sprint.
In a previous discussion, one of the obstacles preventing social media from affecting a positive influence on social capital was the Digital Divide. The problem of course is that like many singular issues, the digital divide is itself made up of multiple caveats.
Article
Note: The article posted for discussion was offline at time of writing.
Discussion
Physical Connection
Connected
This is the most obvious – if you don’t have a connection, you aren’t online. As cited by InternetLiveStats.com approximately 40% of the world’s population is online. This status is meant to sound impressive and it is – but viewed from the opposite angle, that means 60% of the population is NOT online.
Semi-Connected
Being online does not mean one has a quality or even a consistent connection. The statistic of population online is a binary, and a misleading one at that. After all, intermittent and or poor access is still “online”. There is little quantitative data on connection quality, but speculative heuristics paint a bleak picture for most of the 40% who have a connection at all. Only the first world – and not even all of that – enjoys a full fast connection.
Connection quality may sound like more of an annoyance than a real problem, but perspective applies. What we call a poor connection, most of the world calls unimaginable. Furthermore, most online content is designed and built by the very entities with the best connections. This includes government sites, information sources, non-profit organizations, and of course most social media applications.
End result is that as the first world moves more and more of its basic commerce and social interaction online – the rest of the world actually loses access rather than gaining as is a common assumption.
Linguistics
Another obvious issue. English is the language of business. Unfortunately though English is the third largest language by number of speakers – that still leaves most of the world behind a vast and for the moment virtually impenetrable wall of non-communication. As is often the case, it is the world’s poor yet again at the greatest disadvantage, for they are more likely to be native speakers of more obscure dialects, and the least able to obtain access to English education.
As communication goes both ways, native English speakers are often no more well equipped than their non occidental counterparts to deal with a linguistic divide, and many simply have no wish to.
Education
We love to joke about how inept our progenitors are when it comes to online savvy. The classic story of some random grandmother being preyed upon by schemers, scammers, and spammers is more prevalent than ever.
Try to imagine what happen if grandmother wasn’t a first world denizen with access to contemporary education, a modern connection, and the primary language of online communication. Now face the reality – that is exactly the situation most of our world happens resides in.
Online savvy goes well beyond dodging malefactors. The simple act of searching for information is a skill we take for granted. What about typing? Maintaining software? Or for that matter, hardware. There is simply more to getting online than having a neighborhood connection, and for the people who need it the most, it is these skills we consider perfunctory that are the domain of greatest privilege.
Hope
Logistical challenges of bringing the world online at all, let alone at a quality approaching that we in the first enjoy, is both astronomical and growing. Fortunately several entities have risen to take on this challenge. See below for a few in action.
In this preceding article I’d spoke of some reasons why Social Media acts as a detriment to social capital. However, there are several advantages social media offers over traditional media to the engaged citizen.
Two major hypotheses have been postulated in regards to social media vs. social capital:
As social media proliferation increases, the balance of social capital decreases.
As social media proliferation increases, the balance of social capital increases.
As an alternative to these diametrically opposed viewpoints, I would like to propose a third hypothesis:
As social media proliferation increases, the balance of social capital remains constant.
In support, I have already offered points toward social media decreasing social capital. Let us now discuss some of the means by which social media can counteract its own negative effect.
Discussion
Financial Access
An obvious advantage social media offers is potential cost effectiveness. Most social media applications are free to use, offering a powerful tool with cost measured only in time vested.
Furthermore, social media also offers a point of income. Via specific fundraising apps like Kickstarter or gofundme.com or direct fundraising campaigns, citizens and organizations have access to potential fund sources that simply did not exist less than a decade prior.
Global Society
Social media has yet to break down cultural, linguistic, and accessibility barriers, but it’s fair to say physical borders are approaching irrelevance. With a few clicks, one can can communicate with peers and strangers alike from around the world. The simple logistics of organizing a real world meeting is now no more difficult than clicking on a calendar drop-down. And though my previous article made a point of only 40% of the world being online at all, that’s still billions individuals that were just not accessible at all to the average citizen of ten years ago.
Edutainment
Wasn’t this cited as a detriment? Indeed it can be and thanks to Sturgeons Law usually is. That said, one cannot blame the hammer for poor construction. Making informational topics fun and is not a new idea – but social media gives us the power to do so quickly and easily.
Describing how a benefit project to relief victims can be fun and beneficial to society is one thing. Posting a video showing people working together, becoming potential lifelong friends, and the resulting work they’ve done is quite another thing. Only social media gives this kind of power to the average citizen.
Conclusion
It’s not fair to say that I have proven my hypothesis, because I haven’t. There are dozens of points still to discuss, and a lack of hard data for analysis. Even so, on a personal level I believe there is currently a balance. We are no better or worse off in totality – the methodology is just different.
If we want to tip the balance positively, it may help to think of social media for what it is. A tool. Social media for its own sake is worse than useless – used wrong it can quickly escalate to being one of society’s major challenges. But when taken for what it is, a vector, a tool, then it is can be the ultimate trump card toward bringing the world together as never before.
I’ve minced no words in my pessimistic view toward the “power” of social media. To outright repeat myself – I believe the reach and influence of social media, at least in the modern sense is overstated. Social media is by and large a new term, but NOT a new phenomenon. I would argue in fact, that it is not social diversification that has taken place within the last decade, but homogenization – that is to say, the social sphere has compressed itself into a series of internet based applications.
The potential of our public social sphere’s continuous migration into the virtual world is enormous, to the point it defies definition. Unfortunately, potential is NOT power. Until certain issues are resolved, there remains a tenuous balance between the advantages and detriments of social media to social capital. Certainly we cannot hope to tackle even a portion within one discussion, but we can at least the opening gambit.
Discussion
Normally my format of choice is to ask and answer my own pair of questions. For this discussion, let’s instead highlight some specific points and try to take them on piecemeal.
Cyberbalkanization is the segregation of the Internet into smaller groups with similar interests, to a degree that they show a narrow-minded approach to outsiders or those with contradictory views. While the Internet has largely been credited for broadening discussion, it also can serve as a means of bringing together fringe groups with intolerant viewpoints. So, while the Internet has contributed to globalization and information exchange, it also may be used to foster discrimination.
In so many words, it’s human nature. We tend to seek out those with similar opinions for validation and comfort. However, with the fore mentioned homogenization of our information sources into a few small (and controllable) outlets, there is a dangerous precedent of reducing what we know into what we want to know.
Digital Divide
It may shock millennials, Gen-Xers, and perhaps a few Baby Boomers too, but the majority of the world’s population is NOT online. At all. Forget Facebook, Tumbler, and the rest – according to InternetLiveStats.com over 60% of the world populace has yet to experience the musical medley of a dial up modem tone.
It’s simple math – the more our world relies upon online sources of information and commerce, the fewer humans have access to it.
All this only considers having a physical connection. A GOOD connection, basic know how, technology education, online social savvy (cyber street smarts if you will), and linguistic barriers are all obstacles far more difficult to surmount than stringing a bit of fiber optic into third world neighborhoods.
Edutainment
Be honest – how many of you log into your favorite social media to get world news and reports. Be honest again – if you DID log in for education, how many of you wound up watching random videos, looking at friend’s photos, or succumbed to some other distraction?
Human nature strikes again. Combined with Cyberbalkanization, the ratio of frivolous to informative activity is arguably decreasing. End result is an uneducated but highly opinionated populate. If that combination sounds dangerous – it is.
Pseudo Participation
Perhaps better termed “Click Participation”. You will not find this point in our readings as it is my own. In this article among others I have argued a serious degradation to social capital is the self delusion of participation.
It is simply too simple and easy to fool one’s self into a sense of engagement by taking actions online that by and large have absolutely no real effect. An obvious example would be clicking like or posting an offhand comment about a post you agree or sympathize with. More and more specific discussion can be found here,here, and here.
Establishing the concept of social capital is one thing, actually doing something about it is quite another. In a previous article, I argued that engagement is the true key to Social Capital. Let us now address the minutia.
Questions
Q1 – What is engagement?
I’ll admit asking this mostly so I can answer it. To truly gain social capital, I argue physical action must accompany the intent. Clicking like on someone’s post about thinking of disaster victims does nothing to help. Donating to the relief effort does. Or if you do not have the financial resources, showing up and providing physical labor. If that’s not possible, just the simple act of rolling up one’s sleeves and giving a bit of blood makes an actual world affecting contribution.
Similar principles apply to the body politic. What is the difference between posting snarky memes and voting? One of them has an infinitesimal effect on the world, and the other is a snarky quote.
Q2 – How To Engage Using Social Media?
If likes, +1s, and pictures don’t help engage, then what good is social media? Plenty of course. Well written discourse can attract the right kind of attention and raise awareness. Social media groups can be used to coordinate real world efforts. Real time data from ground zero of a project can encourage and cajole.
Simply put, social media has thus far proven to be highly detrimental toward overall social capital. Fortunately in the right hands, it is potentially one of, if not the most powerful tool in the engaged citizen’s arsenal.
This self-contained library is intended to aid in parsing dates and time values regardless of incoming format, and output the result to a uniform format of choice.
The simple fact is that client side inputs are notoriously unreliable. Even when enforcing inputs to choose or sanitize dates, you may not end up with uniform results across browsers. Or even the SAME browser. Google Chrome for instance, will send a different format depending upon seconds input. Even if you enforce seconds using the step attribute, Chrome will not send seconds as part of the date time string if the user chooses a seconds value of 00.
Unless you choose a value of 01 or greater, Chrome simply won’t include seconds.
However, should you choose a seconds value of 01 or more, then Chrome WILL include the seconds when posting. Same browser. Same version. Same field attributes. Yet entirely different formats depending on perfectly valid user inputs.
You could choose to use text fields and invoke heavy JavaScript date/time pickers, but then you harm the mobile experience, where seamless date choosing is already implemented. If you choose a dynamic solution that looks for support of date time fields, then you regain the mobile experience, but you’re right back to dealing with unreliable formatting.
In a nutshell, if you don’t perform server side validation, you may wind up with undefined behavior from whatever code relies on the input. Databases are particularly finicky. Go ahead and send client side dates directly to an RDMS. Your results will be the same as Forrest Gump’s chocolate box.
Unfortunately, most forms of server side validation are themselves rather persnickety. In the above example, a validator expecting seconds will reject input from Chrome, and several mobile browsers as well. This is where my date and time library comes into play. By leveraging a layered approach and PHP’s string to time, we can accept most any valid time string, verify it, and output in a single uniform format for use.
Use
Simple – Object is initialized with default settings:
// Initialize object with default settings.
$dc_time = new dc\Chronofix();
Advanced – Initializing a settings object first, and applying it to the main object.
// Initialize settings object, and use it
// to set date format to Year-Month-Day only.
$dc_time_settings = new dc\Config()
(); $dc_time_settings->set_format('Y-m-d'); // Initialize time library with settings. $dc_time = new dc\Chronofix($dc_time_settings);
Once initialized the following functions are exposed. All examples assume default settings.
$string = '2017-02-15 12:00:00';
echo $time->is_valid($string);
// Outputs TRUE if valid, or FALSE.
For internal use, but exposed for possible utility purposes. Evaluates $string against current date/time format. If the formats match, TRUE is returned. Otherwise FALSE is returned.
Evaluates the current date/time value and attempts to convert its format to the current format setting. Leverages a combination of php’s strtotime and date object to handle nearly any format of dates and times. Outputs newly formatted date/time string, or NULL on failure.
$object = new dc\Config();
$time->set_settings($object);
In the last century we have witnessed a gradual but exponential change in the media consumption habits of society. In the first world even those of lesser means possess fingertip access to the sum of public domain human knowledge and entertainment – all distilled through a twelve centimeter array of light emitting diodes. Of course resolving whether such distillation results in a net positive or detriment would be a debate both furious and never ending.
Questions
Q1 – What IS social capital?
The Webster definition of social capital reads as follows:
the networks of relationships among people who live and work in a particular society, enabling that society to function effectively.
So then, social capital is a network. But how exactly does a network enable a society to function effectively. If individuals are only engaged in self promotion or gain, an oft cited pitfall of social media, how does society benefit? Or does the ability to directly network through Social Media offset the “me” factor enough to actually increase social capital?
Q2 – What is the key to social capital?
Theoretically if social capital is a network, then networking is the key. This is I diverge from Mr. Webster, Dr. Nah, and most of my contemporaries. I would maintain the true key to social capital is engagement. Without taking some action to affect some real change in the physical or even virtual world, all the networking in the world is of no use.